
프로세스 개선을 위한 시뮬레이션 방법
김성희 | 3월 14일, 2022 | 10분 읽기
프로세스 개선을 위해 왜 시뮬레이션을 해야 할까요? 현실에서 프로세스 내 업무 흐름이나 자원의 구성을 바꾸기는 쉽지 않습니다. 예를 들어, 병원에서 의사를 한 명 고용했을 때 환자의 대기시간 감소에 얼마나 영향일 미칠 것인지 쉽게 알기 어렵습니다. 현실에서는 고용을 위한 준비와 절차, 그리고 결과가 나올 때까지 기다려야만 효과를 알 수 있습니다. 즉, 상당한 비용과 시간이 소요됩니다. 반면에, 가상 세계에서는 상대적으로 적은 비용과 시간으로 의사 고용에 대한 효과를 확인해 볼 수 있습니다. 그렇다면 어떻게 프로세스 시뮬레이션을 할 수 있을까요? [그림1]을 보면서 하나씩 알아보도록 하겠습니다.
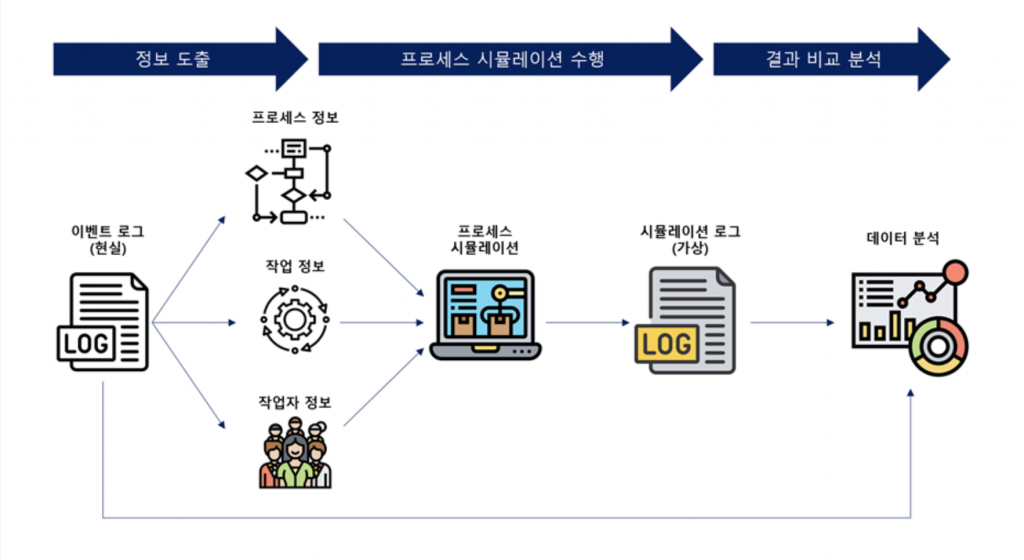
1. 정보 도출
가장 좋은 시뮬레이션 모델은 현실과 매우 유사한 환경을 가져야 하고, 이를 위해 이벤트 로그 데이터를 활용합니다. 따라서, 가장 처음 할 일은 데이터로부터 프로세스를 도출하고, 작업과 작업자 관련 정보를 도출하는 것입니다.
· 프로세스 정보
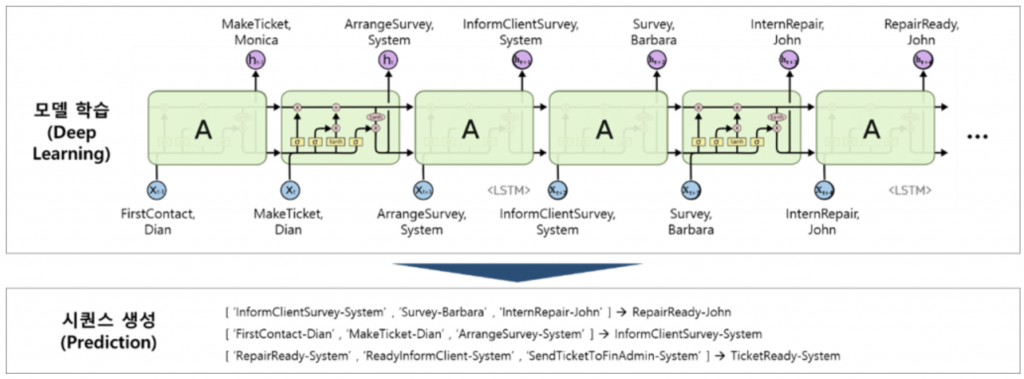
프로세스 정보가 필요한 이유는 케이스가 어떤 작업을 수행할 것인지를 시뮬레이션이 알아야 하기 때문입니다. 그렇다면 어떻게 프로세스 정보를 도출할 수 있을까요? 확률 모델을 활용하는 방법도 있지만 저희는 딥러닝 모델을 사용합니다. 데이터의 각 케이스가 수행한 작업 순서를 하나의 시퀀스라고 간주하여 딥러닝의 시퀀스 모델에 학습을 시킵니다. [그림2]를 보면 연두색이 시퀀스를 학습하는 딥러닝 모델입니다. 이 모델의 역할은 케이스의 과거 작업 & 작업자 조합을 인풋으로 받아 바로 다음 작업 & 작업자 조합을 예측하는 것입니다. 여기서는 프로세스 시뮬레이션의 전반적인 방법에 대해 설명하기 때문에 딥러닝 모델에 대해 상세히 다루지는 않도록 하겠습니다.
· 케이스 정보
케이스 정보에서 가장 중요한 것은 ‘케이스 도착 시간’입니다. 예를 들어, 병원에서 평소에 약 10분마다 새로운 환자가 온다고 가정해 봅시다. 여기서 10분이 평균 케이스 도착 시간입니다. 그런데 환자가 더 짧은 간격으로 오게 된다면 어떻게 될까요? 자연스레 환자의 대기시간도 증가할 것입니다. 이처럼 케이스 도착 시간은 시뮬레이션에서 매우 중요한 요소입니다. 그리고 통계 기법(MLE, ECDF 등)을 활용하여 데이터로부터 케이스 도착 시간에 대한 분포를 추정할 수 있습니다.
· 작업 정보
작업 정보에서 가장 중요한 것은 ‘작업시간’입니다. 앞서 딥러닝을 통해 다음 작업과 작업자를 예측했다고 하면, 그 작업을 얼마나 수행할 것인지도 결정해 주어야 합니다. 작업시간 또한 통계 기법(MLE, ECDF 등)을 활용하여 데이터로부터 추정할 수 있습니다. 그리고 대부분 각 작업에 따라서 작업시간이 다르기 때문에 서로 다른 분포를 추정하도록 합니다.
· 작업자 정보
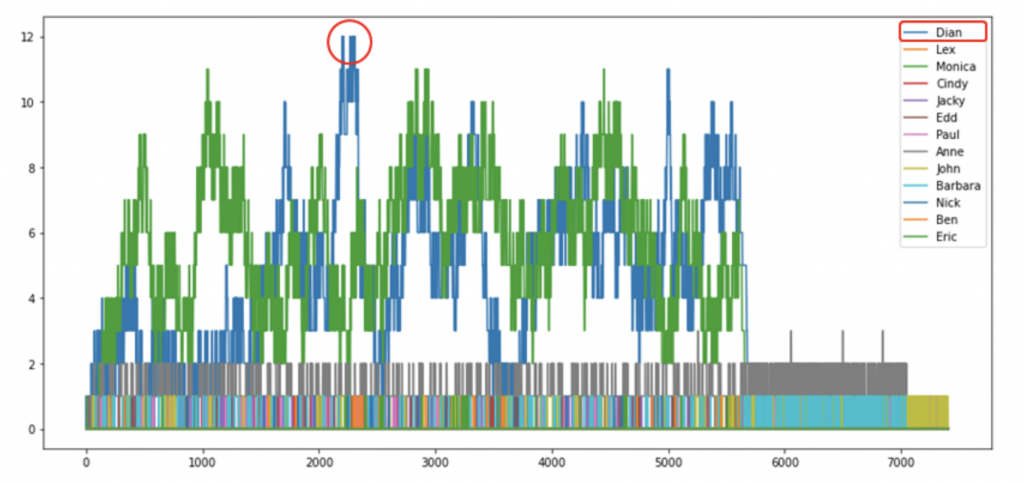
작업자 정보에서 가장 중요한 것은 각 작업자의 업무수행능력(Capacity)입니다. 시뮬레이션에서 업무수행능력이란, 한 작업자가 동시에 수행할 수 있는 작업의 양을 의미합니다. 그리고 작업자는 본인의 업무수행능력보다 더 많은 일을 받았을 때 대기가 발생하게 됩니다. 만약 실제보다 너무 작게 추정하면 현실보다 대기시간이 줄어들 것이고, 반대의 경우 대기시간이 늘어날 것입니다. 이를 추정하는 다양한 방법이 있겠지만 저희는 데이터로부터 각 작업이 시작하고 종료하는 시점을 활용하여 [그림3]과 같이 시간에 따른 작업자 별 부하를 계산하고 최대치를 작업자의 업무수행능력으로 간주합니다. 예를 들어, Dian(파란색)의 업무수행능력은 12개(빨간 동그라미)입니다. 추가로, 작업자 정보에는 업무수행능력뿐만 아니라 작업자별 근무시간, 비용도 포함됩니다. (비용은 관련 데이터가 존재하는 경우에만 도출합니다.)
지금까지 프로세스 시뮬레이션의 전반적인 과정과 정보 도출 방법들을 소개했습니다. 다음 포스팅에서는 도출된 프로세스, 케이스, 작업, 작업자 정보를 바탕으로 시뮬레이션을 수행하는 방법에 대하여 소개드릴 예정입니다. 프로세스 시뮬레이션에 관심 있는 분들께 이 글이 도움이 되었기를 바라며 다음 포스팅도 기대해 주시면 감사하겠습니다.
2. 시뮬레이션 수행
데이터로부터 다양한 정보를 도출함으로써 시뮬레이션 수행을 위한 준비가 끝났습니다. 하지만 기존 데이터와 그대로 시뮬레이션을 한다면 별 의미가 없겠죠? 이제는 정말 분석하고 싶었던 상황을 시뮬레이션 모델에 적용해야 합니다. 예를 들어, 병원 프로세스인 경우 작업자인 의사 수를 늘려볼 수 있고, 하루에 방문하는 환자의 수를 늘려볼 수도 있습니다. 또는, 아직 모든 진료 프로세스를 완료하지 않은 환자에 대하여 진료를 마치기까지 걸리는 시간을 예측해 볼 수도 있습니다. 이렇듯 시뮬레이션에서는 프로세스 개선을 위한 다양한 상황을 가정할 수 있습니다. 사용자가 원하는 상황에 관련된 옵션을 변경한 후, 이제 시뮬레이션은 가상의 이벤트 로그를 생성하기 시작합니다.
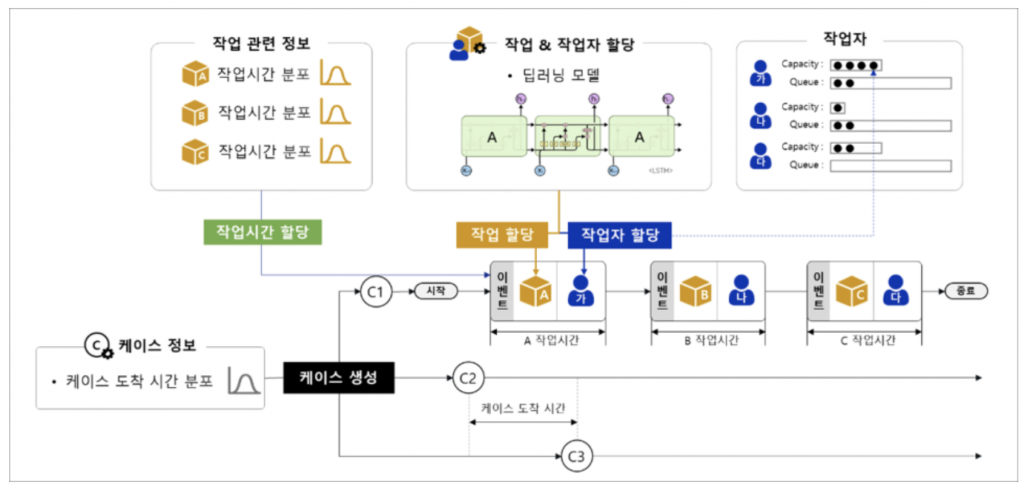
[그림4]는 시뮬레이션 엔진이 로그를 생성하는 과정을 나타낸 그림입니다. 우선 가상의 케이스를 생성합니다. 이때 각 케이스 간 간격은 앞서 데이터로부터 도출한 케이스 도착 시간 분포를 활용하여 랜덤하게 할당합니다. 다음으로 가운데 위쪽에 위치한 딥러닝 모델이 각 케이스가 수행할 작업과 작업자를 할당하면, 작업시간 분포로부터 해당 작업에 대한 작업시간을 랜덤하게 생성합니다. 앞서 배정된 작업자의 작업 리스트에는 일이 쌓이고 업무수행능력(Capacity)을 넘어가게 되면 대기열(Queue)에 쌓입니다. 이와 같은 과정을 반복하여 모든 케이스가 모든 작업들을 종료할 때까지 시뮬레이션을 수행합니다.

시뮬레이션이 진행되고 있는 모습을 시각화하여 볼 수도 있습니다. [그림5]는 시뮬레이션이 수행하는 과정을 보여주는 애니메이션입니다. 검은 동그라미는 하나의 케이스를 나타내고, 마름모는 프로세스 내 작업을 의미합니다. 케이스가 일렬로 쌓이는 것은 해당 작업을 하기 위해 케이스가 대기하고 있는 것입니다. 특정 작업에 대기가 쌓이는 이유는 해당 작업을 수행하는 작업자의 업무수행능력보다 더 많은 일이 몰려왔기 때문입니다.
3. 결과 비교 분석
시뮬레이션을 수행하여 가상의 로그가 생성되었다면, 이제 기존 데이터와 비교하여 얼마나 효과가 있었는지 분석해야 합니다. [그림5]는 Prodiscovery 3.0에서 개발중인 시뮬레이션 분석 대시보드입니다. 차트 내에서 파란색으로 표시된 글자 및 그래프들은 모두 기존 데이터에 대한 정보를 나타내고, 반대로 분홍색은 시뮬레이션 로그에 대한 내용을 의미합니다. 대시보드를 통해 두 데이터 간 프로세스 맵, 케이스 또는 이벤트 개수, 시간(leadtime), 비용, 작업시간 등 다양한 KPI를 한눈에 비교 분석할 수 있습니다.
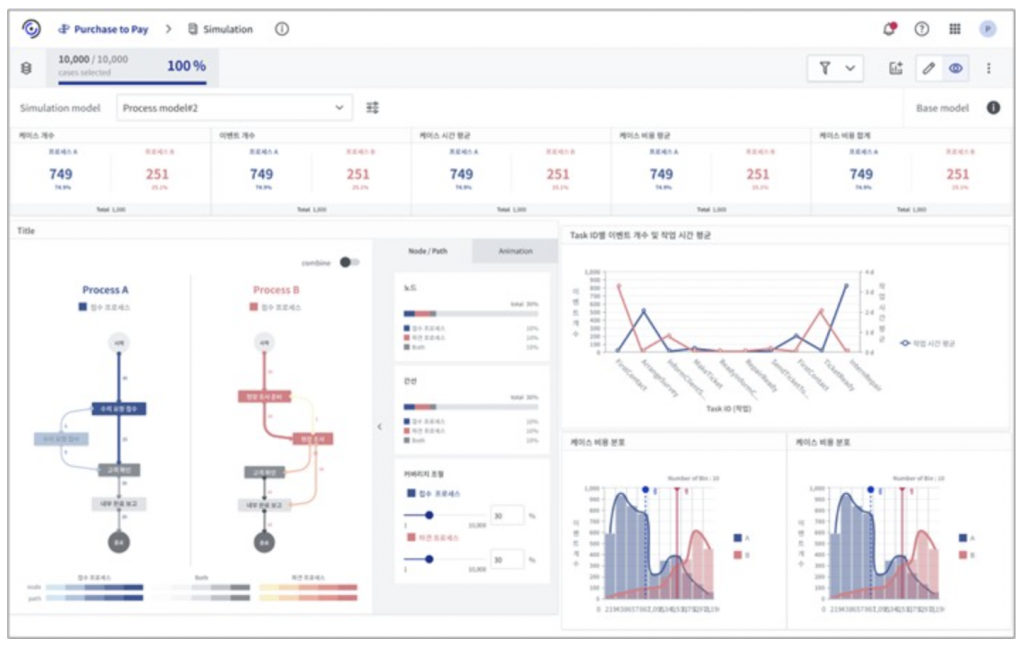
지금까지 프로세스 시뮬레이션에 대한 전반적인 방법론을 소개하였습니다. 이 글을 다 보셨다면 프로세스 시뮬레이션이 어떻게 작동하는지 큰 그림을 볼 수 있을 것이라 생각합니다. 본 포스팅에 언급된 모든 내용은 Prodiscovery 3.0에서 제공할 프로세스 시뮬레이션에 구현되어 있으며 앞으로 다양한 프로세스 개선에 활용될 것이라 기대하고 있습니다. 그럼 많은 관심 부탁드립니다!
#퍼즐데이터 #프로디스커버리 #프로세스마이닝 #PuzzleData #ProDiscovery #processmining #프로세스인텔리전스 #ProcessIntelligence #RPA #BPM #BI #datamining #디지털트랜스포메이션 #디지털혁신 #프로세스혁신 #digitaltransformation #Webinar #업무혁신 #TaskMining #태스크마이닝 #고객여정 #프로세스분석 #데이터분석 #프로세스개선