
프로세스 마이닝에서 Case ID의 의미와 선정 방법
고원휘 | 1월 18일, 2022 | 15분 읽기
프로세스 마이닝에서 필수 요소는 Case ID, Activity, Timestamp 3가지 요소가 존재합니다. 필수 요소에 관해 다시 간단하게 정의하면 다음과 같습니다.
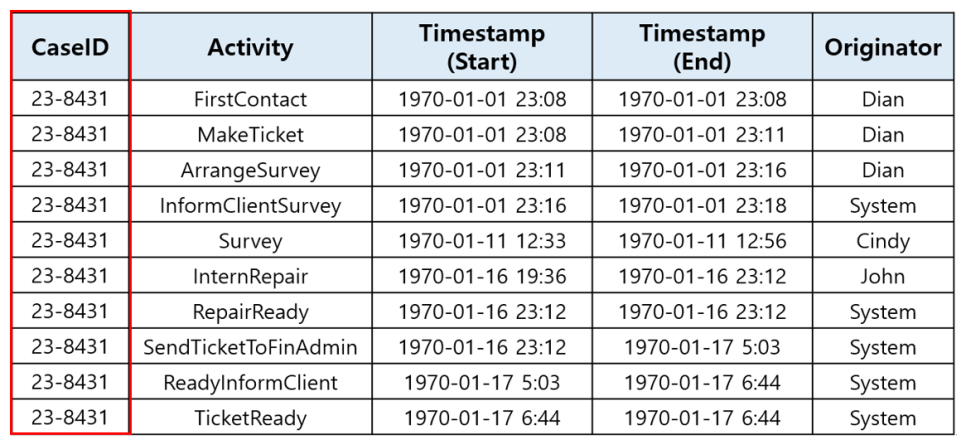
● Case ID : 하나의 프로세스를 표현할 수 있는 열. 프로세스는 시작과 종료가 존재하고 프로세스가 시작하고 종료할 때까지 동일한 값을 가지고 있는 열을 Case ID로 선정한다.
● Activity : 프로세스가 진행되며 해당 프로세스의 업무(Task)를 표현할 수 있는 열. 프로세스를 진행하며 업무를 잘 표현하는 값을 가진 열을 Activity로 선정한다.
● Timestamp : 프로세스가 진행되며 업무가 수행되는 시간을 표현할 수 있는 열. Event log가 기록된 시간 값이 있는 열을 선정한다.
하지만 이런 간단한 설명만을 가지곤 필수 요소에 관해서 이해하기 쉽지 않습니다. 오늘은 필수 요소 중 Case ID에 의미에 관하여 자세히 파악하고자 합니다.
처음 데이터 셋을 살펴보면 어떤 열을 Case ID로 선택할지 난감합니다. 그 이유는 프로세스 마이닝에서 Case ID를 지정하는 행위가 어떤 의미를 가지는지 이해하지 못했기 때문입니다. Case ID를 지정하는 행위의 의미를 파악하면 데이터 셋에서 Case ID를 쉽게 선택할 수 있습니다.
Case ID의 간단한 정의는 하나의 프로세스를 표현할 수 있는 열입니다. 하지만 전 그것보단 프로세스의 범위를 결정하는 열이 더 적절하다고 생각합니다. 따라서 Case ID를 지정하는 행위는 프로세스의 범위를 지정하는 행위입니다. 예시 데이터를 통해 자세히 설명하겠습니다.
데이터 분석 프로세스는 다음과 같은 프로세스를 가집니다.

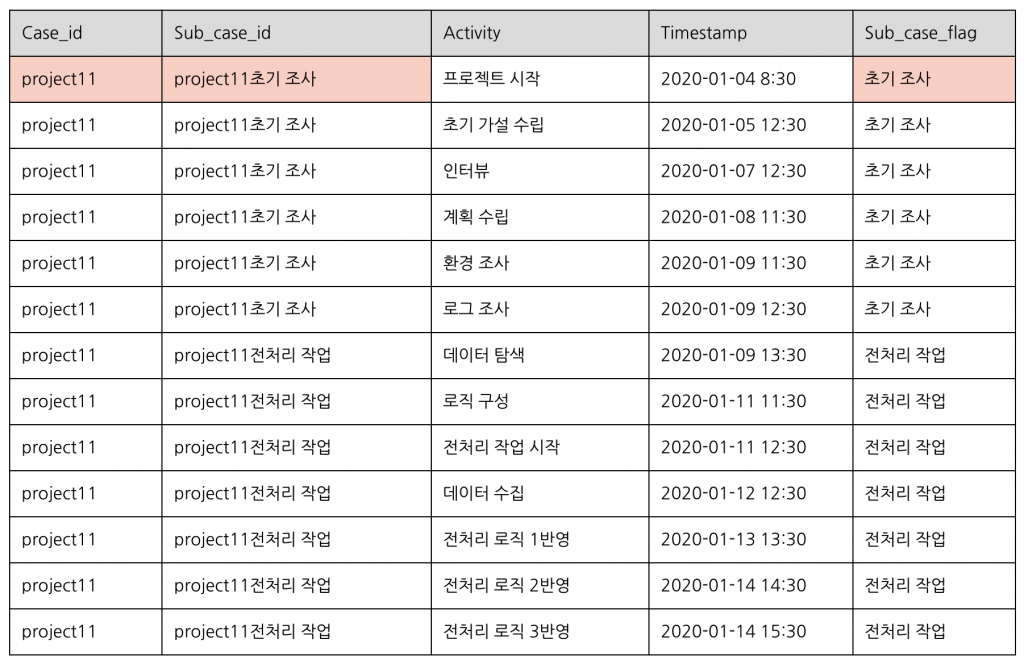
예시 데이터 셋(원본)은 다음과 같습니다.
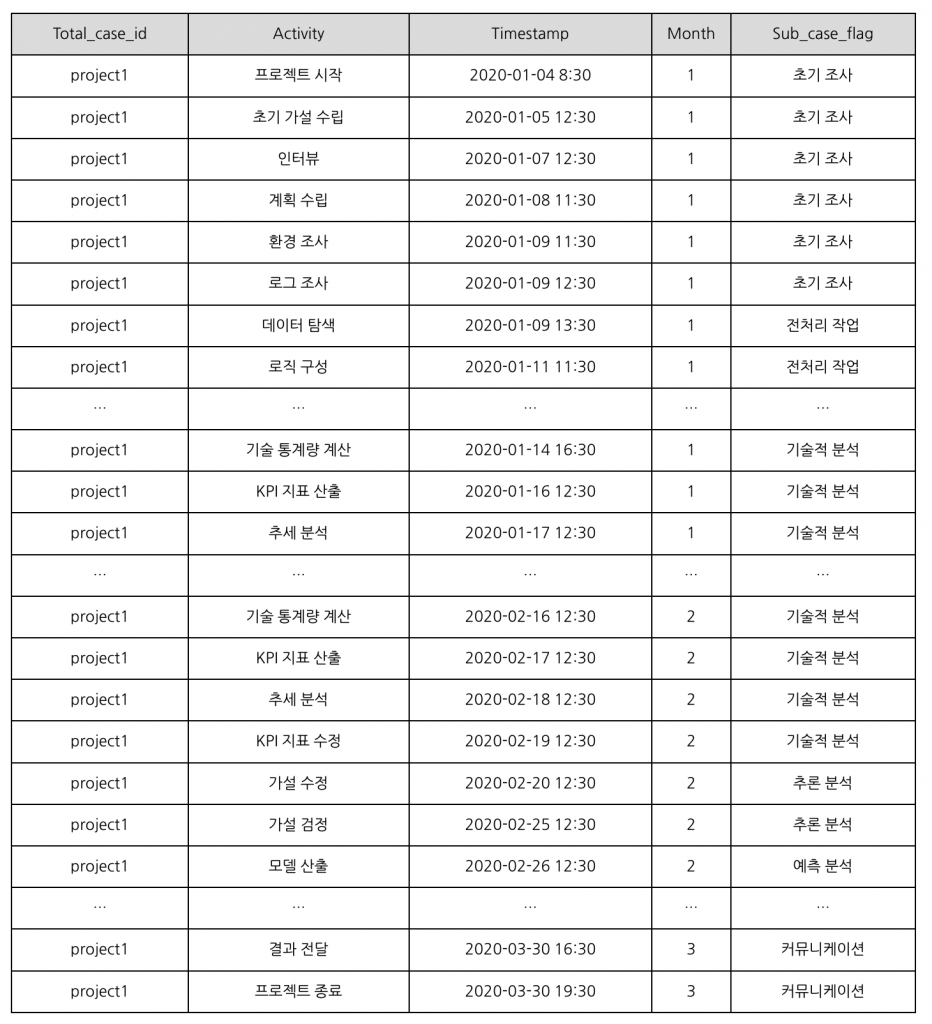
해당 데이터 셋은 데이터 분석 프로젝트를 진행하며 기록된 이벤트 로그입니다. 프로젝트는 총 3달에 걸쳐 진행되었습니다. 1월/2월/3월 각 월마다 1개의 주제로, 총 3개의 주제에 대해 분석을 진행했습니다.
각 열에 대한 설명은 다음과 같습니다.
● Total_case_id : 프로젝트 명
● Activity : 프로젝트를 진행하며 수행한 업무
● Timestamp : 업무가 시작할 때 기록된 시간
● Month : 업무를 수행한 달
● Sub_case_flag : 데이터 분석 프로젝트를 진행하며 수행하는 작업의 성격
Case ID : Total_case_id
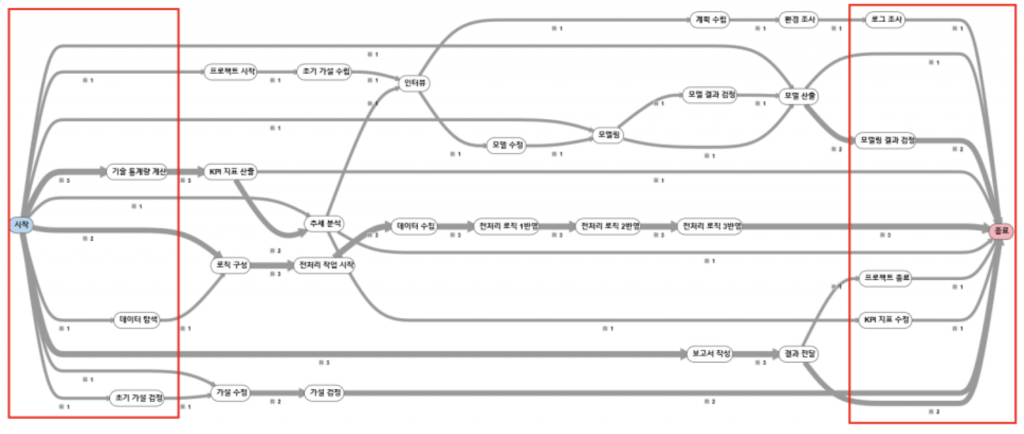
저는 데이터 분석 프로젝트에 대하여 프로세스 분석을 하기로 결정했습니다. 프로젝트 하나가 하나의 프로세스입니다. 예시 데이터에서 project1 프로젝트의 시작과 끝은 프로젝트 시작/프로젝트 종료 업무입니다. 프로젝트 시작/프로젝트 종료까지 동일한 값을 가진 열은 Total_case_id입니다. 그래서 Total_case_id를 Case ID로 지정하였고 프로세스 맵으로 표현하면 다음과 같습니다.

프로세스의 시작이 프로젝트 시작 Activity, 프로세스의 종료가 프로젝트 종료 Activity로 표현된 것을 확인할 수 있습니다.

한 가지 특이한 부분은 결과 Activity 다음에 로직 구성 Activity로 다시 돌아가는 부분을 확인할 수 있습니다. 그 이유는 실제 데이터에서 결과 전달 후, 새로운 주제로 넘어갈 때 로직 구성부터 activity가 시작하기 때문입니다.
Case ID : Case_id
이번에 저는 한 주제에 관한 데이터 분석 프로세스에 대하여 프로세스 분석을 하기로 결정했습니다. 예시 데이터 셋에는 한 주제에 관한 데이터 분석 프로세스의 시작과 종료를 알려주는 열이 없습니다. 하지만 우리에게 각 월마다 1개의 주제를 진행했다는 정보가 있고, month 열이 존재합니다. Total_case_id와 Month 열을 결합한다면, 한 주제에 관한 데이터 분석 프로세스의 시작과 종료를 나타내는 열을 얻을 수 있습니다.
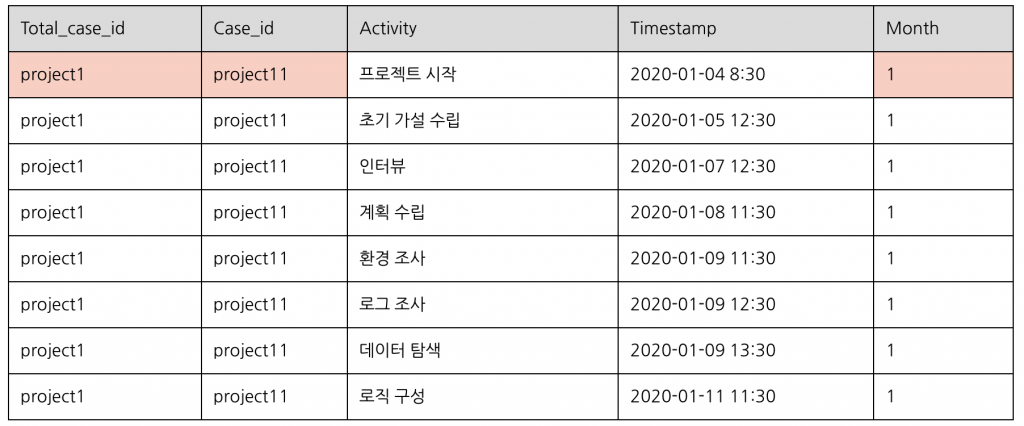
Case_id = Total_case_id + Month
Case_id를 Case ID로 지정하고 프로세스 맵으로 표현하면 다음과 같습니다.

같은 데이터를 사용하였지만 프로세스 맵이 변화했습니다. 가장 큰 변화는 프로세스 시작이 프로젝트 시작 Activity와 로직 구성 Activity 두개로 나뉘었고 프로세스 종료가 결과 전달 Activity와 프로젝트 종료 Activity로 나뉘었습니다.

프로세스 맵은 크게 두 개의 구역으로 나뉘는데 위 구역은 프로젝트 초기 데이터 탐색을 진행한 프로세스이며, 아래 구역은 일상적으로 진행하는 데이터 전처리 → 탐색적 분석 → 모델링 → 결과 전달의 프로세스를 따르고 있습니다.
Case ID : Sub_case_id
프로세스 마이닝은 시스템 로그를 사용하기 때문에 주로 낮은 수준의 log를 기록합니다. 우리가 알고 있는 데이터 분석 프로세스와 달리 기록된 Event log는 더 낮은 수준이 기록되었습니다. 그래서 종종 전체 프로세스의 일부(Sub 프로세스)를 분석하는 것이 더 적합한 경우가 존재합니다.
예시) Sub 프로세스-데이터 전처리
이번에 저는 데이터 분석 프로세스 중 데이터 전처리 단계를 프로세스 분석을 하기로 결정했습니다. 예시 데이터 셋에는 Sub 프로세스의 시작과 종료를 알려주는 열이 없습니다. 하지만 데이터 분석 프로세스에서 작업의 성격을 알려주는 Sub_case_flag열이 존재합니다. Case_id와 Sub_case_flag열을 결합한다면, 데이터 전처리 단계의 시작과 종료를 나타내는 열을 얻을 수 있습니다.
Sub_case_id = Case_id + Sub_case_flag
Sub_case_id를 Case ID로 지정하고 프로세스 맵으로 표현하면 다음과 같습니다.
프로세스 맵이 다시 변화했습니다. 프로세스의 시작과 종료의 종류가 다양 해졌고, 프로세스의 평균 길이가 짧아졌습니다. 즉 프로세스가 분리되어 세분화되었습니다. 세분화된 프로세스는 전체 프로세스의 하위 단계를 표현한 Sub 프로세스입니다.
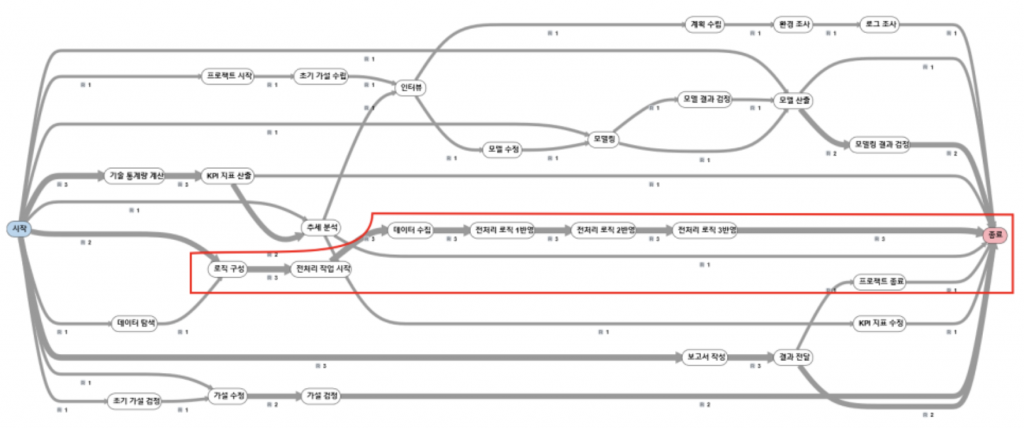
표시한 부분은 데이터 분석 프로세스에서 전처리 프로세스를 나타내는 부분입니다. 필터를 사용해서 해당 프로세스만 표현하면 아래와 같은 그림으로 나타낼 수 있습니다.

제가 분석할 프로세스를 변경할 때마다, 프로세스의 범위가 변화합니다. 그리고 범위의 변화에 맞춰 Case ID가 변화하고, 변화한 Case ID에 따라 프로세스 맵도 변화한 것을 확인하셨습니다. 저는 데이터에서 어떤 열을 선택해서 Case ID를 지정하는 게 아니라, 분석할 프로세스를 정하고 해당 프로세스를 표현하는 열을 Case ID로 지정하거나 여러 정보를 결합하여 Case ID를 생성한 후 지정했습니다.
로그 데이터에서 프로세스 마이닝을 적용하고자 결정했다면, 저처럼 분석할 프로세스를 명확하게 정의하고 데이터에서 Case ID를 지정하는 방법을 추천합니다.
Case ID를 변경하는데 한 가지 유의할 점이 있습니다. Case ID가 변경되면 프로세스 맵뿐 아니라 ProDiscovery 내부의 모든 퍼즐의 통계 값이 변화합니다.
제가 Process Map을 예시로 든 이유는 시각적으로 확인하기 쉽기 때문에 예시를 들었을 뿐, ProDiscovery 내부에선 Case ID가 변화하면 Process Map뿐 아니라, 모든 정보들이 변경됩니다.
설명에 앞서 Process Model에 대해서 이야기하겠습니다. Process Model의 종류는 다양합니다. 예를 들어 개발자들은 프로세스를 모델링 하기 위해 flow chart를 사용하거나, Network를 모델링 하기 위해 페트리 넷을 사용하며, 프로세스 분석가들은 업무 Process를 모델링 하기 위해 BPMN을 사용합니다. 보통 프로세스 flow 외에 많은 정보를 같이 모델링 하는 BPMN을 한번 예로 들어보겠습니다.
아래는 BPMN으로 업무 Process를 모델링 한 예시입니다.
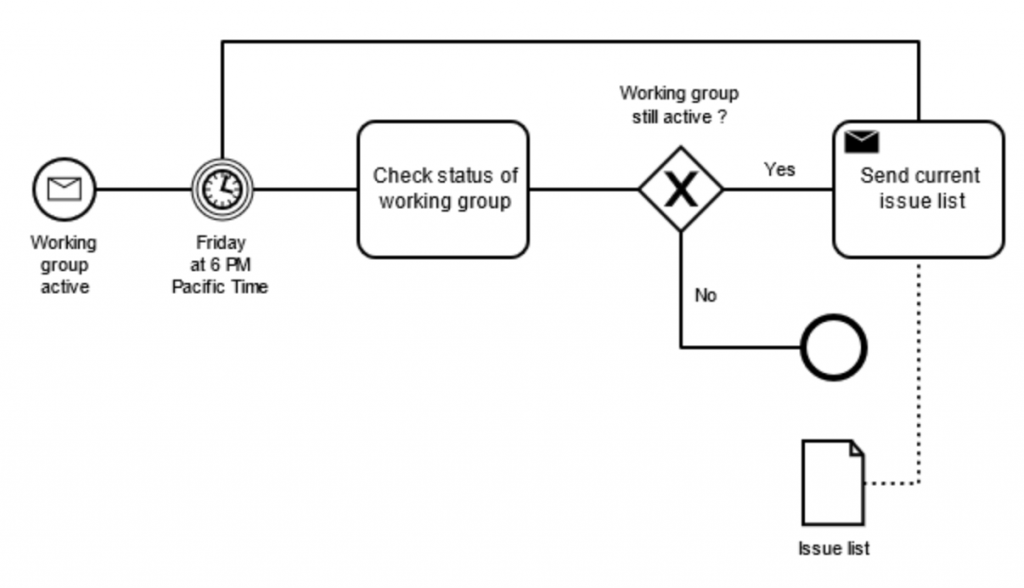
예시의 Process Model은 Process의 flow뿐 아니라, 의사결정, 규칙, 연관 자원 등이 표현되어 있습니다. 실제 Process Model은 Activity의 순서만으로 한정되지 않습니다. 목적에 따라 Process의 여러 맥락적인 정보(Actor, Personal, Social, External, Process, …)가 같이 표현될 수 있습니다.
Process Mining은 log 데이터를 이용하여 Process Model을 자동으로 도출합니다. 이때 필요한 정보는 오직 Case, Activity, Order입니다. 아래 Process Mining Event log concept을 확인하면, 필수 정보로 Case, Activity, (Position/Timestamp) 중 택 1임을 확인할 수 있습니다. Position/Timestamp 택 1인 이유는 둘 중 하나의 정보가 존재한다면, Activity의 순서를 알 수 있고 이를 통해 기본적인 Process flow를 모델링 할 수 있기 때문입니다.
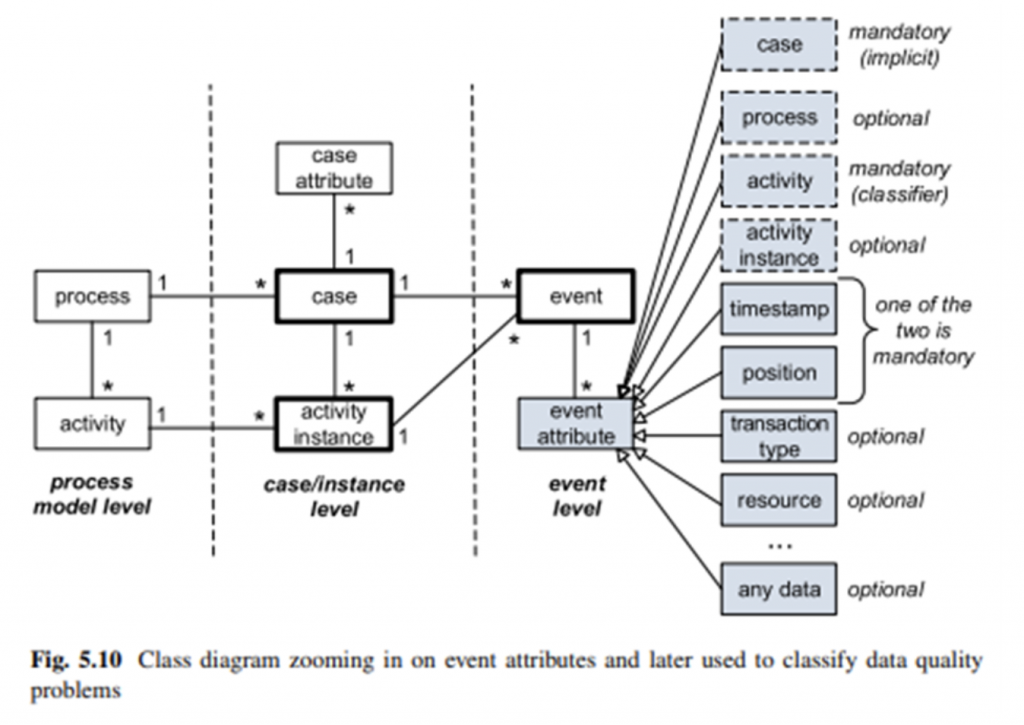
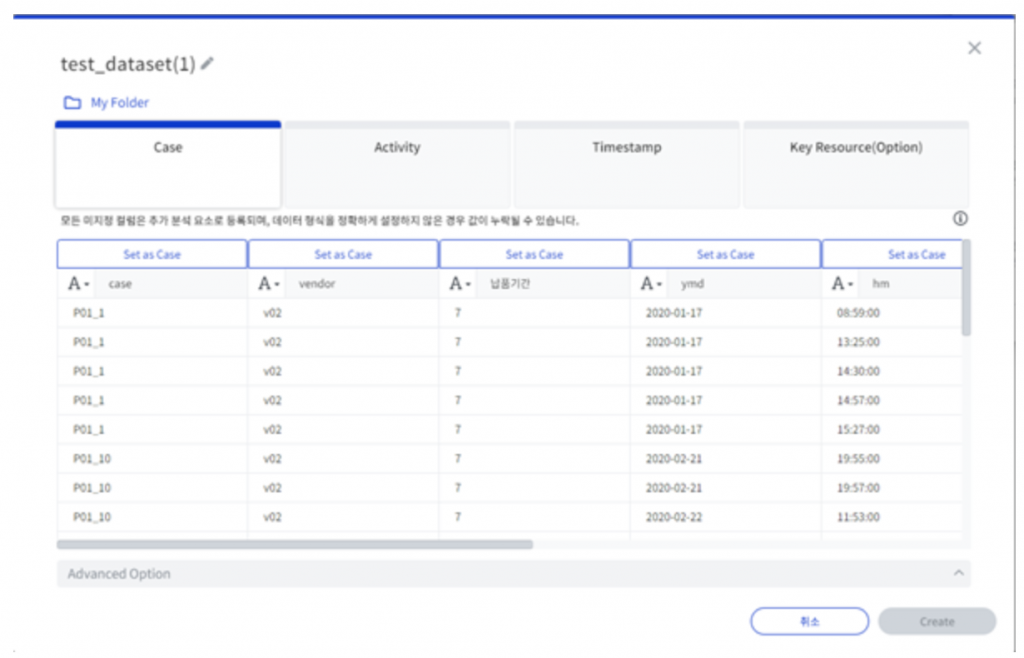
현재 ProDiscovery는 Position/Timestamp 중 Timestamp만을 지원합니다. 이벤트 소스에 Dataset을 생성할 때 Case, Activity, Timestamp를 필수 요소로 지정합니다. 실제 대부분의 IT 시스템에선 log 데이터에 position 정보가 없고, Timestamp가 기록되기 때문에 Timestamp만 사용해도 큰 문제가 없습니다.
Timestamp를 기본으로 사용하기 때문에 ProDiscovery에선 시간을 기준으로 performance 정보를 자동 생성합니다. 이때 모든 시간 계산의 기준은 Case ID를 기준으로 합니다. 프로세스 마이닝에서 Case ID의 의미와 선정 방법에서 도출했던 각 Process Model의 Overview 통계량을 살펴보면 다음과 같습니다.
Total Case ID

Case ID

Sub Case ID
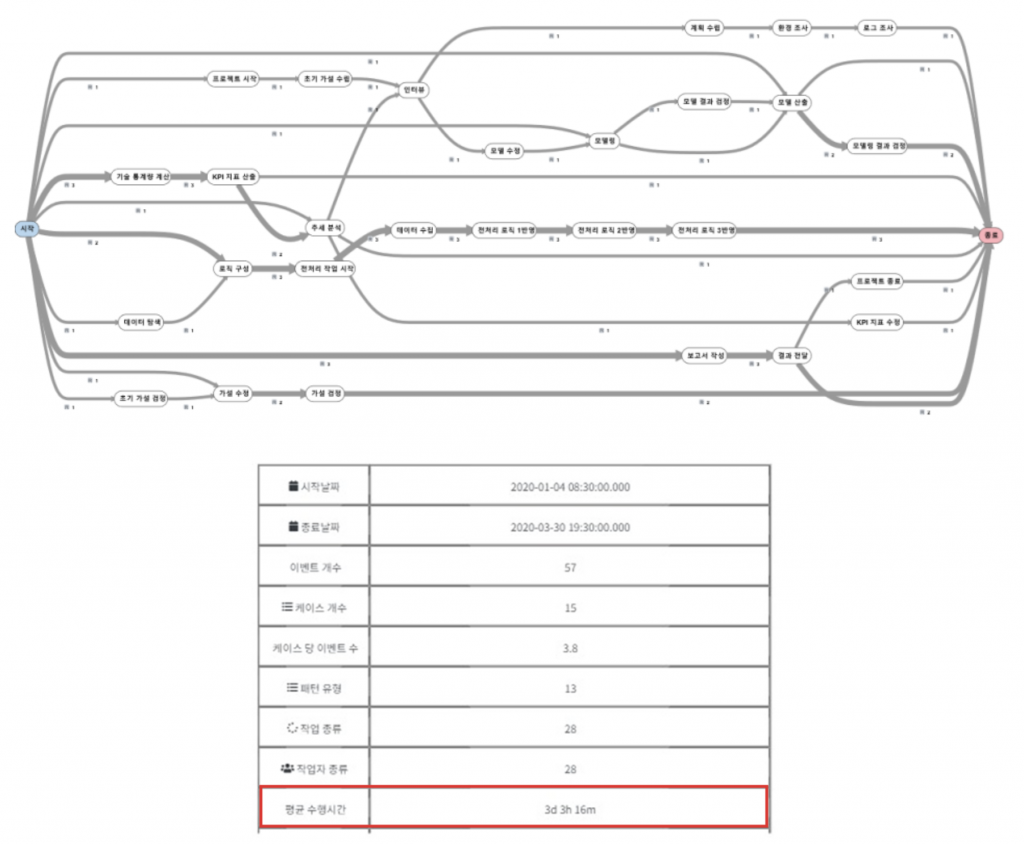
Total Case ID / Case ID / Sub Case ID를 각각 기준으로 할 때 대표적인 통계량인 프로세스 평균 수행 시간이 각각 2M 26d / 20d 23h / 3d 3h로 변화하였습니다. 언뜻 이해가 안 될 수도 있지만 Case ID를 정하는 방법을 생각하면 이런 변화는 당연합니다. Case ID는 분석할 프로세스의 범위를 나타냅니다. 즉 Case ID가 변화하면 프로세스의 범위가 변화하기 때문에 수행 시간도 변화합니다. Total Case ID의 평균 수행 시간은 하나의 프로젝트의 수행 시간이기 때문에 평균 2달 26일 소요된 것이며, Case ID의 평균 수행 시간은 하나의 주제를 분석에 소요된 시간이므로 평균 20일 23시간이 소요되며, Sub Case ID의 평균 수행 시간은 분석 프로세스의 하나의 단계에 소요된 시간이므로 평균 3일 3시간이 소요됩니다.
또 한 가지 주의해야 할 점이 존재합니다. Total Case ID의 총 수행 시간은 2달 26 => 약 2075시간입니다. Case ID의 총 수행 시간은 20일 23시간 * 3 => 약 1509 시간입니다. 이 둘의 차이점을 의아하게 생각하는 경우가 존재합니다. 이런 차이가 발생하는 이유는 Case ID에서 하나의 주제가 끝난 후, 그다음에 시작하는 주제의 대기 시간이 Total Case ID에는 포함되어 있기 때문입니다.

붉은색으로 표시된 부분이 Case ID의 하나의 주제가 끝나고 다음 주제로 넘어갈 때까지 기다리는 대기시간입니다. 이를 데이터로 확인하면 다음과 같습니다.
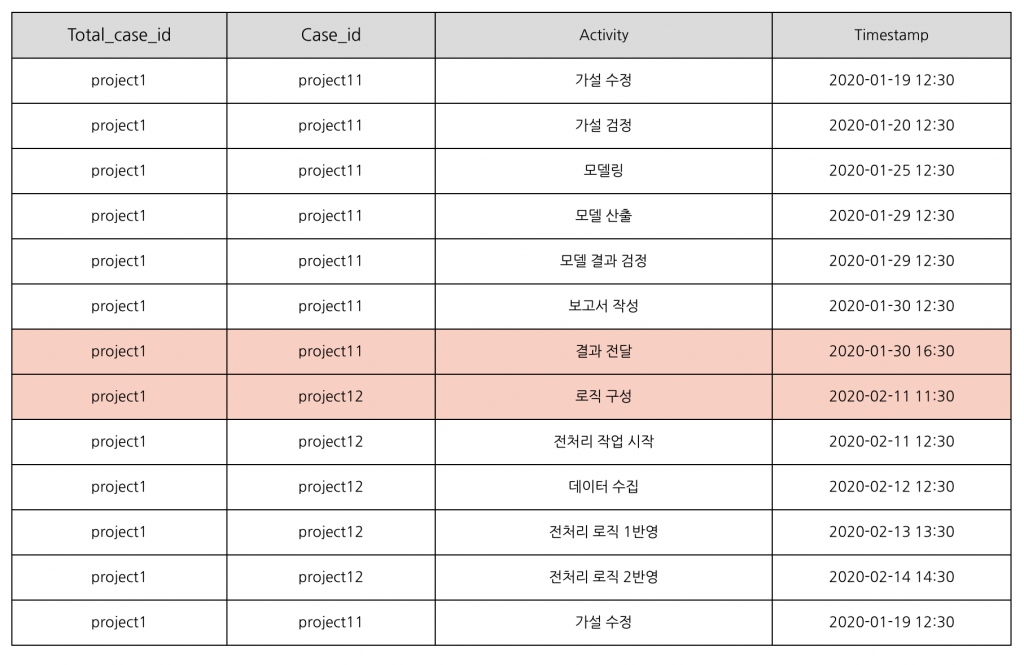
Total Case ID를 사용할 경우 2020-01-30 16:30 ~ 2020-02-11 11:30 사이의 시간이 대기시간으로 수행 시간에 포함되지만, Case ID를 사용할 경우 2020-01-30 16:30 ~ 2020-02-11 11:30 사이의 시간은 수행 시간에서 제외됩니다.
이를 유념하여 (Process-Sub Process)와 같은 위계를 가진 프로세스를 분석할 경우, sub process를 분석할 때 sub process => sub process로 넘어가는 대기시간이 포함되지 않는다는 것을 주의하여 분석해야 합니다.