

프로세스 개선을 위해 왜 시뮬레이션을 해야 할까요? 현실에서 프로세스 내 업무 흐름이나 자원의 구성을 바꾸기는 쉽지 않습니다. 예를 들어, 병원에서 의사를 한 명 고용했을 때 환자의 대기시간 감소에 얼마나 영향일 미칠 것인지 쉽게 알기 어렵습니다. 현실에서는 고용을 위한 준비와 절차, 그리고 결과가 나올 때까지 기다려야만 효과를 알 수 있습니다. 즉, 상당한 비용과 시간이 소요됩니다. 반면에, 가상 세계에서는 상대적으로 적은 비용과 시간으로 의사 고용에 대한 효과를 확인해 볼 수 있습니다. 그렇다면 어떻게 프로세스 시뮬레이션을 할 수 있을까요? [그림1]을 보면서 하나씩 알아보도록 하겠습니다.
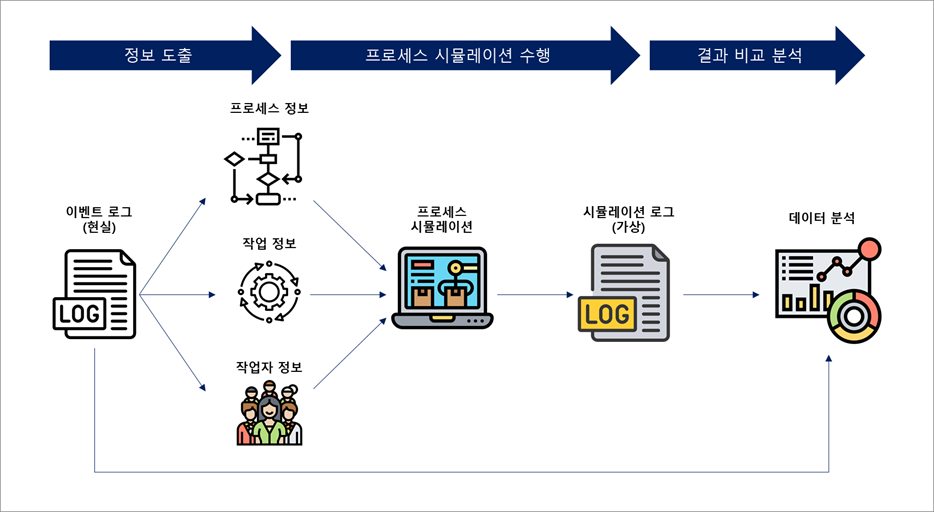
[그림1] 프로세스 시뮬레이션 방법
- 정보 도출
가장 좋은 시뮬레이션 모델은 현실과 매우 유사한 환경을 가져야 하고, 이를 위해 이벤트 로그 데이터를 활용합니다. 따라서, 가장 처음 할 일은 데이터로부터 프로세스를 도출하고, 작업과 작업자 관련 정보를 도출하는 것입니다.
- 프로세스 정보
프로세스 정보가 필요한 이유는 케이스가 어떤 작업을 수행할 것인지를 시뮬레이션이 알아야 하기 때문입니다. 그렇다면 어떻게 프로세스 정보를 도출할 수 있을까요? 확률 모델을 활용하는 방법도 있지만 저희는 딥러닝 모델을 사용합니다. 데이터의 각 케이스가 수행한 작업 순서를 하나의 시퀀스라고 간주하여 딥러닝의 시퀀스 모델에 학습을 시킵니다. [그림2]를 보면 연두색이 시퀀스를 학습하는 딥러닝 모델입니다. 이 모델의 역할은 케이스의 과거 작업 & 작업자 조합을 인풋으로 받아 바로 다음 작업 & 작업자 조합을 예측하는 것입니다. 여기서는 프로세스 시뮬레이션의 전반적인 방법에 대해 설명하기 때문에 딥러닝 모델에 대해 상세히 다루지는 않도록 하겠습니다.
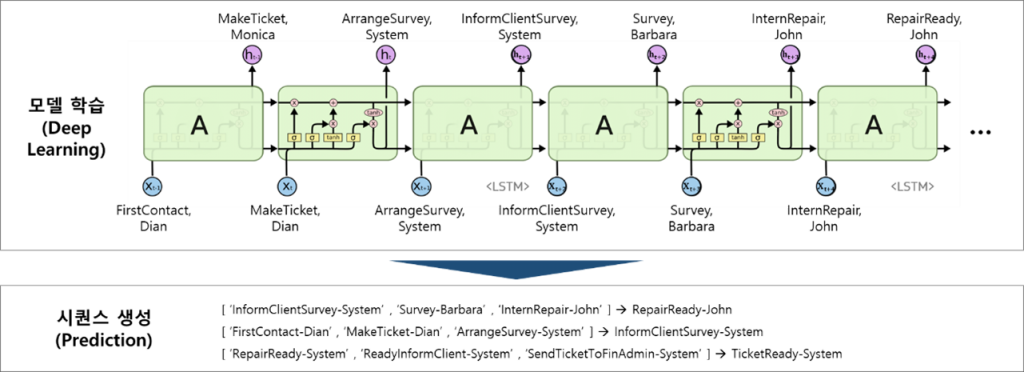
[그림2] 딥러닝 기반의 시퀀스 학습 예시
- 케이스 정보
케이스 정보에서 가장 중요한 것은 ‘케이스 도착 시간’입니다. 예를 들어, 병원에서 평소에 약 10분 마다 새로운 환자가 온다고 가정해봅시다. 여기서 10분이 평균 케이스 도착 시간입니다. 그런데 환자가 더 짧은 간격으로 오게 된다면 어떻게 될까요? 자연스레 환자의 대기시간도 증가할 것입니다. 이처럼 케이스 도착 시간은 시뮬레이션에서 매우 중요한 요소입니다. 그리고 통계 기법(MLE, ECDF 등)을 활용하여 데이터로부터 케이스 도착 시간에 대한 분포를 추정할 수 있습니다.
- 작업 정보
작업 정보에서 가장 중요한 것은 ‘작업시간’입니다. 앞서 딥러닝을 통해 다음 작업과 작업자를 예측했다고 하면, 그 작업을 얼마나 수행할 것인지도 결정해주어야 합니다. 작업시간 또한 통계 기법(MLE, ECDF 등)을 활용하여 데이터로부터 추정할 수 있습니다. 그리고 대부분 각 작업에 따라서 작업시간이 다르기 때문에 서로 다른 분포를 추정하도록 합니다.
- 작업자 정보
작업자 정보에서 가장 중요한 것은 각 작업자의 업무수행능력(Capacity)입니다. 시뮬레이션에서 업무수행능력이란, 한 작업자가 동시에 수행할 수 있는 작업의 양을 의미합니다. 그리고 작업자는 본인의 업무수행능력보다 더 많은 일을 받았을 때 대기가 발생하게 됩니다. 만약 실제보다 너무 작게 추정하면 현실보다 대기시간이 줄어들 것이고, 반대의 경우 대기시간이 늘어날 것입니다. 이를 추정하는 다양한 방법이 있겠지만 저희는 데이터로부터 각 작업이 시작하고 종료하는 시점을 활용하여 [그림3]과 같이 시간에 따른 작업자 별 부하를 계산하고 최대치를 작업자의 업무수행능력으로 간주합니다. 예를 들어, Dian(파란색)의 업무수행능력은 12개(빨간 동그라미)입니다. 추가로, 작업자 정보에는 업무수행능력 뿐만 아니라 작업자별 근무시간, 비용도 포함됩니다. (비용은 관련 데이터가 존재하는 경우에만 도출합니다.)
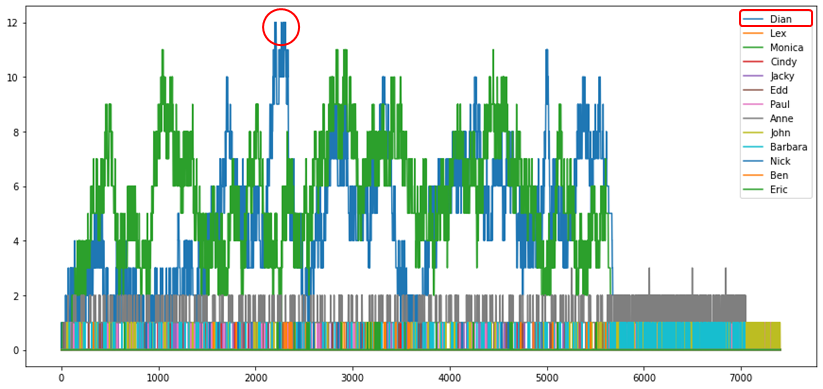
[그림3] 작업자 별 작업 부하 그래프 예시
지금까지 프로세스 시뮬레이션의 전반적인 과정과 정보 도출 방법들을 소개했습니다. 다음 포스팅에서는 도출된 프로세스, 케이스, 작업, 작업자 정보를 바탕으로 시뮬레이션을 수행하는 방법에 대하여 소개드릴 예정입니다. 프로세스 시뮬레이션에 관심 있는 분들께 이 글이 도움이 되었기를 바라며 다음 포스팅도 기대해주시면 감사하겠습니다.
