
ProDiscovery(프로디스커버리)에 데이터를 등록하는 방법
먼저 CSV 형태로 된 이벤트 원본 파일(txt 파일)을 준비합니다. 이벤트 원본 파일에는 특정 분류 값 및 작업, 작업자, 수행 일시 등에 대한 정보가 있습니다.(“프로세스 마이닝 분석을 위한 데이터 요소”편 참고)
데이터집합에 데이터를 관리할 폴더를 새로 생성합니다.
데이터집합 옆의 “+” 버튼을 눌러 폴더를 생성합니다.
여기서는 “수리데이터” 라는 이름으로 생성했습니다.

글자를 입력 후 Enter 키 또는 확인 버튼을 누르면 폴더가 생성됩니다.
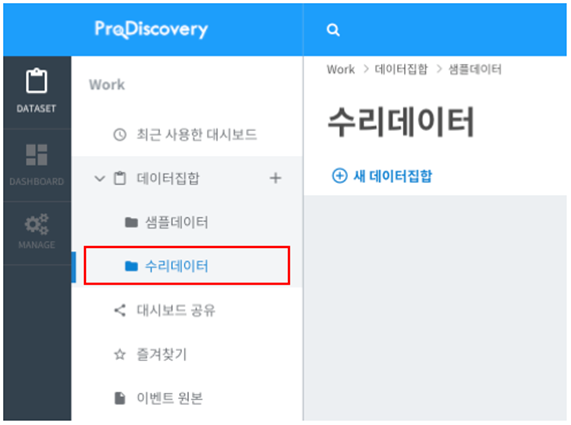
새 데이터집합을 생성합니다
생성한 “수리데이터” 폴더를 선택하여 이동 후 “새 데이터집합” 버튼을 누르면 데이터 집합 등록 화면이 표시됩니다.
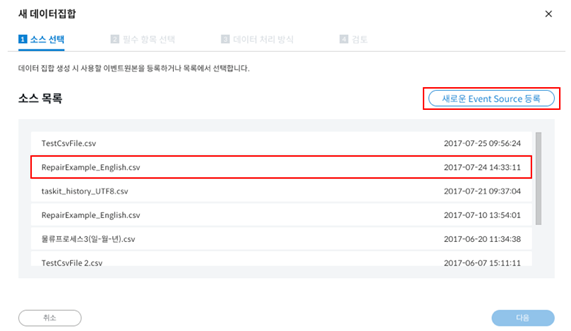
“새로운 Event Source 등록” 을 통해 PC에 가지고 있는 CSV 파일을 등록하거나 이미 기존에 등록했던 파일들 중 선택해서 진행할 수 있습니다.
CSV 환경 설정을 합니다.
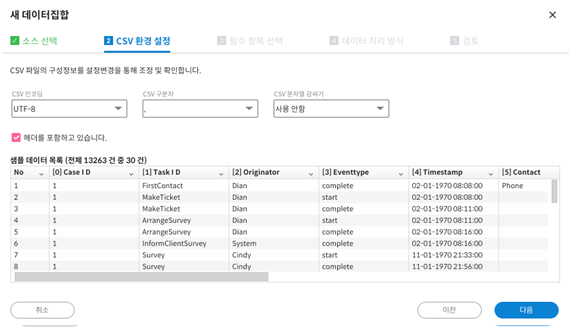
CSV는 다양한 형태로 구성이 가능한 파일 포맷입니다. Text 파일이기 때문에 국내 특성상 한글 인코딩 방식을 설정하거나(한글로 된 글자가 깨져서 표시될 경우 인코딩 방식을 변경해봅니다) 각 컬럼을 구분하는 구분자(콤마 또는 탭)을 설정하고 또, 하나의 컬럼을 이루고 있는 데이터의 문자열을 문장 부호(따옴표 또는 쌍따옴표)를 통해 감싸는 경우가 있는데 이를 설정할 수 있습니다. 보통 컬럼 데이터가 구분자를 포함하고 있는 경우 문자열 감싸기를 사용해서 데이터와 구분자를 분류해줍니다.
CSV 환경 설정을 마치면 해당 설정을 바탕으로 샘플데이터를 읽어오게 됩니다.
원본데이터를 프로세스마이닝 하기 위한 ‘필수 항목 선택’을 진행합니다.
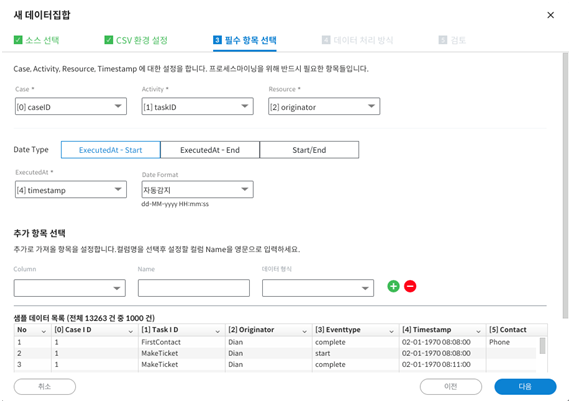
“필수 항목 선택”에서는 Case, Activity, Resource, Date를 지정하게 됩니다.
Case, Activity, Resource는 실제 데이터에 따라 다양하게 설정할 수 있으며 분석 결과는 완전히 달라지게 됩니다.
Date Type 은 기록된 이벤트가 시작하는 시점에 기록을 했는지 또는 끝나는 시간에 기록을 했는지에 따라 달리 설정할 수 있습니다. 이에 따라 통계 값들이 달라지게 됩니다. Start/End 의 경우 시작과 종료 시간이 모두 기록되어 있는 경우에 지정하면 되며 이 경우 가장 정확한 통계 값을 제공합니다.
Date Format 은 Text 형식의 날짜 데이터를 시스템이 자동으로 판단해줍니다. 보통 년-월-일 또는 월-일-년, 일-월-년 과 같은 다양한 유형이 날짜 데이터 형식이 존재하는데 샘플데이터 1000건을 기준으로 판단하여 결과를 보여줍니다. 시스템이 판단한 결과와 실제 데이터가 일치하지 않을 경우 수동으로 설정 가능합니다. 수동인 경우 년-월-일 순서만 지정해주면 나머지는 시스템에서 자동으로 판단합니다.
데이터 처리 방식 옵션 설정
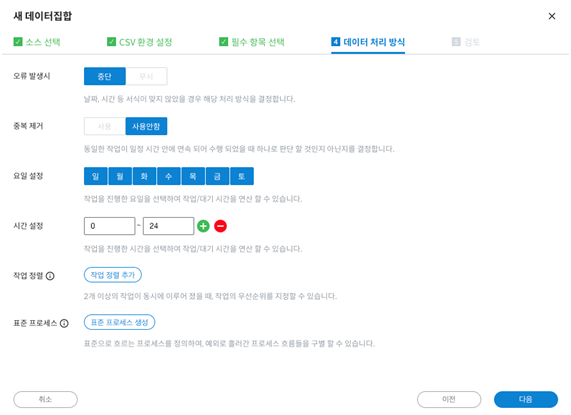
필수 항목 설정이 끝나면 데이터 처리 방식에 대한 설정을 할 수 있습니다. 여기서는 시간 데이터를 기준으로 작업시간을 계산하는데 어떻게 계산할지에 대한 내용이 주를 이룹니다. 예를 들어 월~금 요일까지 의 데이터만, 9시부터 18시까지의 데이터만을 사용해서 작업시간을 계산하고 싶을 때 설정 가능합니다.
이 설정값들은 데이터를 필터링하는 건 아니고 작업시간을 계산하는 용도로만 사용합니다.
그 외에도 동일한 시간에 발생한 이벤트의 순서를 지정하는 작업 정렬과 표준 프로세스를 지정해 일치 여부를 진단하는 설정 등을 할 수 있습니다.
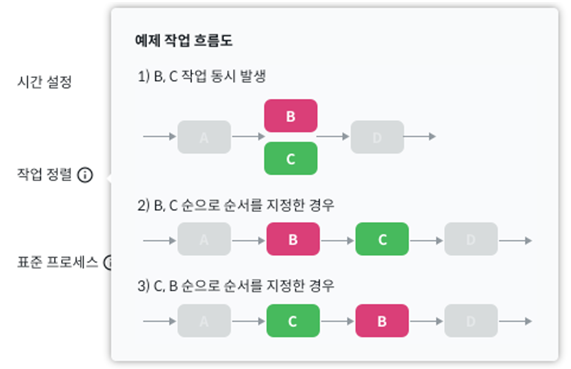
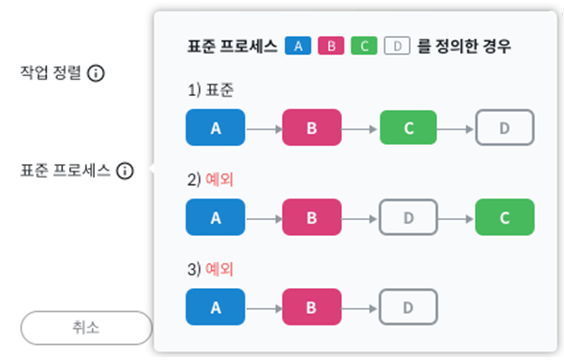
설정한 모든 내용을 검토합니다.
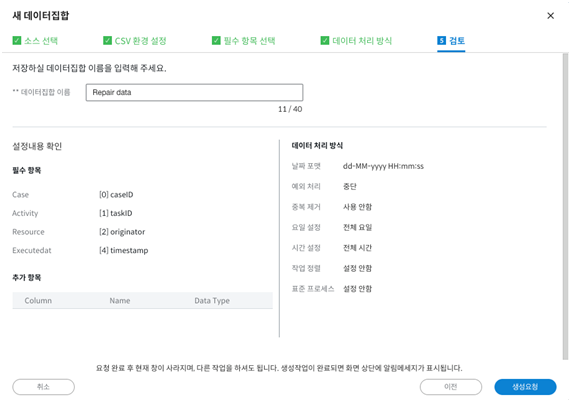
지금까지 설정한 모든 내용을 리뷰하고 데이터집합의 이름을 설정합니다. 데이터 집합은 나중에 변경할 수 있습니다.
필수 항목 및 데이터처리 옵션은 데이터집합을 생성하고 난 뒤에는 수정이 불가능합니다. 다른 설정을 사용하고 싶으면 다시 원본데이터를 기준으로 새 데이터집합을 생성하면 됩니다. 여러 유형으로 데이터집합을 생성 후 비교해볼 수 있는 기능을 제공하기 때문에 간단하게 여러 방법으로 설정을 할 수 있습니다.
데이터 집합 생성이 완료되면 아래와 같이 집합에 대한 기본 정보를 목록에서 확인할 수 있습니다.
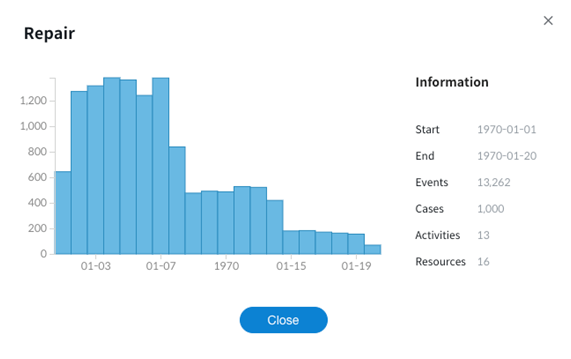
이후에는 대시보드를 생성해서 데이터 분석을 시작하게 됩니다.
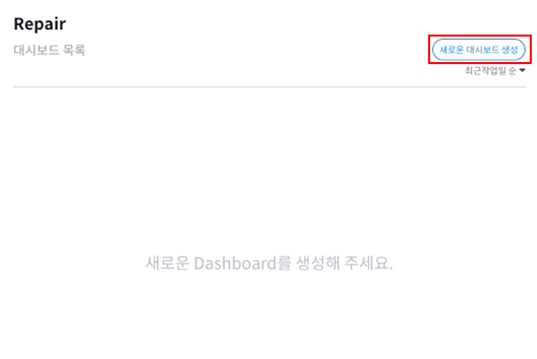
새로운 대시보드 생성 버튼을 누르면 대시보드가 새로 생성되며 바로 대시보드 화면으로 이동됩니다.
여기까지 ProDiscovery에 간단하게 데이터를 등록하는 방법에 대해 살펴보았습니다. 필수 항목을 선택하는 방법에 대해서는 이전의 “프로세스 마이닝 분석을 위한 데이터 요소” 편을 참고하시기 바랍니다.