
프알못(프로세스 마이닝을 알지 못하는 1인)의 ProDiscovery 체험기
저는 요새 핫한 기술인 빅 데이터, 프로세스 마이닝, AI 등에 호기심과 관심은 많지만 아직 아는 것보다 알아야 할 것이 더 많은 신규 직원입니다. 지금까지 직장생활을 하는 동안 금융권 시스템과 애플리케이션에서 찍어내는 수없이 많은 로그 데이터를 봐왔습니다. 하지만, 그렇게 많은 로그를 찍어내면서도 제대로 활용한 사례는 거의 없다는 것이 큰 문제였습니다. 에러나 장애는 예측 불가능한 것이었고, 장애가 발생하더라도 수동으로 로그에서 문제점을 찾아내고 분석해야 했습니다. 이런 순간들이 쌓이고 쌓이면서 빅데이터와 프로세스 마이닝에 대한 필요성을 깊이 느끼게 되었고, 그 간절한 염원 하나로 운 좋게 퍼즐데이터에 입사하게 되었습니다. 이런 제가 처음으로 사용해 본 프로디스커버리(ProDiscovery) 후기를 공개합니다.
프로세스에 대한 지식 없이도 도출 가능한 패턴 분석 툴
오늘 사용할 데이터는 제품의 A/S 수행 기록이 담긴 이벤트 로그 샘플 데이터입니다. (아래 표 참조)

샘플 데이터는 총 9,551개의 레코드로 구성된 이벤트 로그 파일로, 데이터 필드는 Case ID, Task ID, Start Timestamp, Complete Timestamp, Originator로 이루어져 있습니다.
– Case ID: A/S 의뢰된 제품 일련번호
– Task ID: A/S과정 중 발생하는 업무 이벤트
– Start Timestamp: 업무 시작 시각
– Complete Timestamp: 업무 종료 시각
– Originator: 해당 업무 담당자
그럼 이 데이터 파일을 가지고 프로디스커버리(ProDiscovery)에서 의미 있는 패턴을 찾아보도록 하겠습니다.
파일 업로드만으로 낱개의 로그 데이터에서 흐름이 읽혀지다
ProDiscovery에서 프로세스 패턴 추출은, 가지고 있는 로그 데이터를 업로드하는 것부터 시작합니다. 낱개로 흩어져 있는 데이터로부터 의미 있는 흐름을 도출해 내는 것이 중요하며, 데이터를 업로드하는 순간부터 패턴 분석을 위한 전처리가 시작됩니다.

데이터 파일을 ProDiscovery에 업로드하는 자세한 방법은 기존에 작성된 [ProDiscovery(프로디스커버리)에 데이터를 등록하는 방법]이라는 글이 있어 생략하였습니다. 저는 몇 번의 클릭과 1~2분의 기다림으로 데이터 집합이 생성되었습니다.
https://blog.naver.com/prodiscovery/221066221480
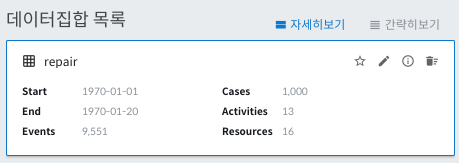
로그 데이터로만 보았을 때는 이벤트가 기록된 단순 파일이었던 것이, 등록을 진행하자 새로운 정보들을 보여주기 시작했습니다.
파일에 있던 9,551개의 레코드에서 1,000개의 case가 검출되었고, 13개의 activity와 16개의 resource가 추출되었습니다.
생성된 데이터 집합을 통해 Dash board로 들어가니 Performance, Process Analysis, Process Map, Basic Analysis, Social Network 등의 카테고리에 포함된 다양한 퍼즐 리스트를 볼 수 있습니다.
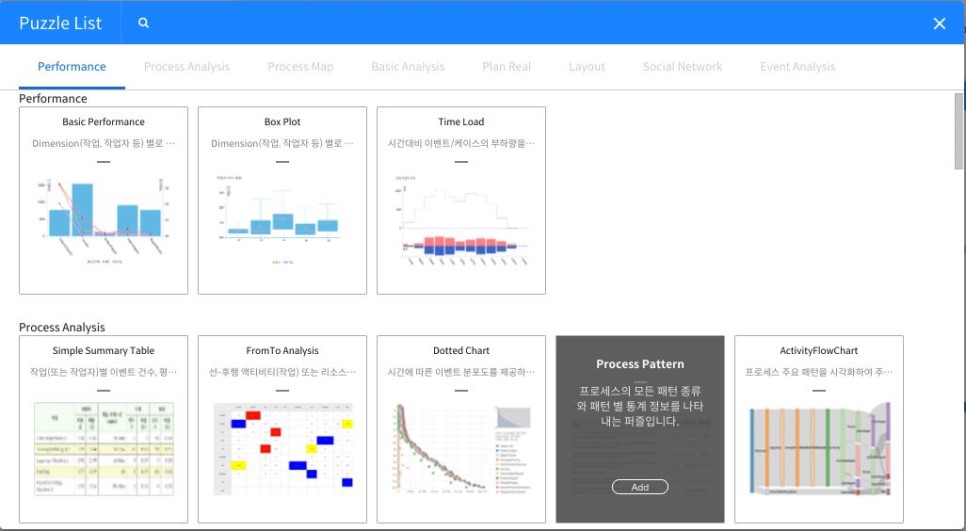
저는 이 많은 퍼즐들 중 ‘액티비티(작업)의 빈도 수를 기반으로 도출한 프로세스 맵’이라고 소개된 [Frequency Based Mining]을 선택하였습니다.
퍼즐을 활용한 분석 내용

dash board에 출력된 map을 보면 프알못(프로세스 마이닝은 물론 데이터 분석조차 알지 못하는 1인)인 제가 보기에도 다음과 같은 사실을 아주 쉽게 알아낼 수 있었습니다.
1. A/S 프로세스는 FirstContact > MakeTicket > ArrangeSurvey > InformClientSurvey > Survey > ImmediateRepair 또는 InternRepair > RepairReady > SendTicketToFin-Admin > ReadyInformClient > TicketReady 의 업무 흐름으로 진행이 됨.
2. A/S를 의뢰받은 1,000개의 case 중 초기 연락(FirstContact) 진행 후 73개의 case가 사라짐. 눈 앞에 도출된 결과를 통해 FirstContact 진행 시 A/S가 불가능한 제품을 걸러낸 것인지, 비용 발생 등 특정한 이유로 고객이 A/S를 포기한 것인지, 다른 이유로 누락이 발생한 것인지 등 다양한 예상을 수립하고 조사를 진행할 수 있음.
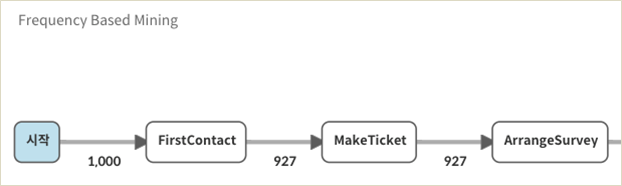
3. Survey 후 ImmediateRepair 또는 InterRepair가 진행되며 수리(Repair)가 완료되면 최종 담당자에게 Ticket이 가거나 Client에게 완료 안내가 전달됨.

(Survey 후 TicketReady에 이르기까지 case 숫자의 합이 927개를 유지하지 않는 이유는 ImmediateRepair와 InterRepair 업무의 진행 시간 차이 때문인 것으로 보임. [Frequency Based Mining] 맵과 연동되는 다른 퍼즐로 살펴보았을 때, ImmediateRepair는 1시간 이내에 마무리되며 InterRepair는 1주일 정도 소요되는 것으로 나타났음.)
4. SendTicketToFinAdmin과 ReadyInformClient 사이에 업무가 순조롭게 마무리되지 않고 서로 토스되는 현상이 나타남. 이에 대한 분석이 필요함.
무엇이 문제인지, 객관적 분석이 가능하다.
ProDiscovery에서 제공하는 각 퍼즐들은 무수히 많은 분석 기능을 담고 있습니다. 모든 퍼즐에는 다양하고 특정한 조건에 따라 필터를 적용할 수 있으며, 앞서 맛보기로 살펴본 [Frequency Based Mining] 맵의 경우 위의 기능뿐만 아니라 해당 맵으로부터 연동되는 여러 개의 퍼즐과 차트를 가지고 있습니다.
ProDiscovery를 처음 사용해본 제가 느낀 점은, 많은 시간과 노력을 들이지 않고서도 프로세스를 그려보고 패턴을 분석하고 문제가 되는 부분이 어디인지 명확히 객관적으로 진단하는 것이 가능하다는 것이었습니다.
앞서 말씀드린 ‘금융권 시스템과 애플리케이션에서 찍어내지만 사용되지 못하고 사라지던 그 수없이 많은 로그 데이터’가 ProDiscovery를 만나면 문제점을 찾고, 분석할 수 있는 살아있는 데이터가 된다는 것입니다.
앞으로 데이터와 프로세스 마이닝을 통하여 엄청난 변화와 혁신이 일어날 것이라는 확신이 생깁니다. 하루빨리 많은 분야에 ProDiscovery를 소개하고 적용할 수 있도록 더욱 노력하겠습니다.
