
프로세스 마이닝(Process Mining) 분석 시스템 구축
데이터 분석 및 처리를 지원하는 새로운 기술들은 계속 소개되고 있으며, 프로세스 마이닝 분석 도구 역시 예외 없이 이러한 기술들을 사용하여 구현됩니다.
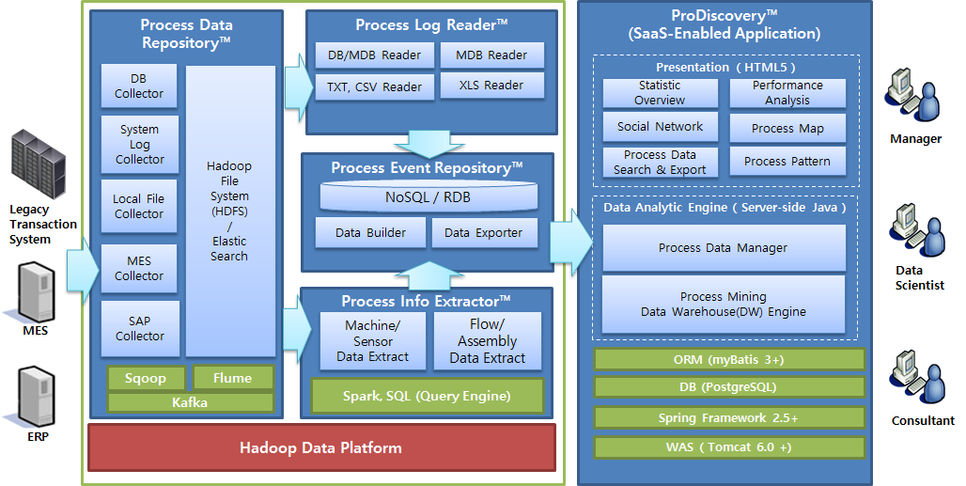
다음은 프로세스 마이닝 시스템 구현 시 고려해 볼 수 있는 오픈 소스 기술들입니다.
데이터 수집 관련 기술 : Apache Flume, Sqoop
프로세스 마이닝 분석 적용을 위한 데이터가 간단히 CSV 형태로 사용자 PC에 존재하여 업로드하는 방식도 있지만, 대용량 데이터 처리를 위해 하둡 파일 시스템(HDFS)에 저장되는 방식이 많이 사용됩니다. 이때, 하둡 생태계에 속한 데이터 수집 관련 오픈 소스 기술들이 마찬가지로 사용될 수 있습니다.
Flume은 데이터를 수집하는 대표적인 기술로 다양한 이벤트 소스로부터 일반적인 로그 수집 기능을 구현하기 위해 사용됩니다. 이외 Apache Kafka, Storm 등 실시간 데이터를 좀 더 안정적으로 분산 처리하기 위한 기술도 같이 고려해 볼 수 있습니다. 이외에도 분석하고자 하는 업무 로그가 RDBMS에 저장되어 있다면, RDB의 데이터를 가져오기 위해서 Sqoop 등이 사용됩니다.
시스템 메타 데이터 관리 : PostgreSQL
데이터를 일회성으로 분석하는 것이 아니라, 데이터 집합을 속성별로 관리하고, 보안 및 공유 등 기업용 시스템으로서 부가적인 기능이 필요할 수 있습니다.
이때, 로그인 시스템, 공유 시스템, 사용자 관리 등 메타 데이터를 저장하고 관리하기 위해 RDBMS를 사용합니다. 이중 PostgreSQL은 대표적인 오픈소스 계열의 RDBMS로서 라이선스에 대한 부담 없이 상용 목적의 설치 및 배포 등이 자유롭다는 장점을 가집니다.
PostgreSQL은 대용량 데이터의 조회 및 입력 속도가 다른 NoSQL 계열의 DB에 비해 느리지만, SQL 등을 통해 데이터 조작성이 용이하다는 장점이 있습니다. 따라서, 데이터 전처리 및 원본 데이터의 저장 등 빅데이터 처리보다는 분석된 데이터의 통계 결과값, 가공된 요약 정보를 저장하여 필요할 때 조회하는 목적으로 사용되기도 합니다.
이벤트 데이터 저장 및 검색 : ElasticSearch
ElasticSearch는 검색엔진 라이브러리 루씬을 기반으로 하는 오픈 소스 검색 솔루션으로 최근 검색 이외의 로그 저장 및 분석의 목적으로도 많이 활용되고 있습니다. 검색 속도에 강점을 가지고 있는 만큼 각 케이스별로 이벤트 데이터를 저장하고, 인덱싱하여 대용량 이벤트 데이터를 빠른 속도로 질의하고, 여러 서버 노드에 쉽게 확장하고 분산 질의할 수 있는 기능을 제공합니다. 이렇게 검색에 최적화된 구조를 통해 프로세스 마이닝 구현 스택에서는 이벤트 원본 데이터 조회 및 이벤트 속성에 따른 OLAP(Online Analytical Processing) 분석 용도로 사용될 수 있습니다.
하지만 개발자나 분석가가 일반적으로 널리 사용되는 SQL(Structured Query Language)보다는 DSL(domain-specific language)이라 불리는 쿼리 문법을 별도로 익혀야 합니다. 그리고, 조인(join) 등 관계형 데이터베이스에서 사용되는 서로 다른 테이블 간 상호 참조하는 쿼리를 지원하기 위해서는 이벤트 중심의 자료 구조 및 인덱스 모델 설계에 좀 더 신경 써야 하는 부분이 존재합니다.
데이터 전처리 가공 : Apache Spark
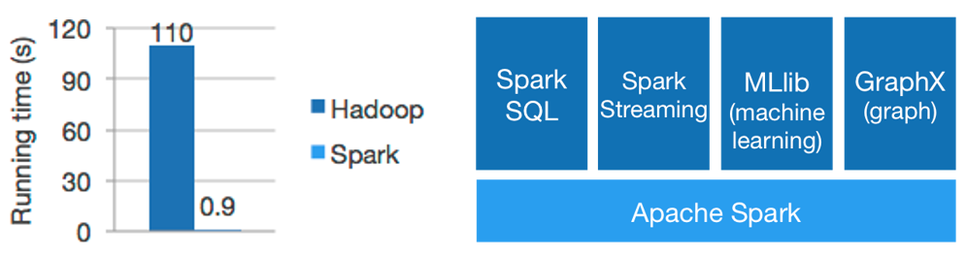
Apache Spark는 기존 하둡의 맵리듀스(Map-Reduce)를 대신하는 데이터 처리 방안으로 자리 잡고 있습니다. 하둡 Map-Reduce가 파일 시스템의 IO의 병목으로 처리 속도가 중요하지 않은 대용량 배치 처리에 적합하다면, Apache Spark는 In-memory 방식의 데이터 처리 기법을 채택하여 보다 빠른 성능을 보여줍니다. 이외 기본 라이브러리를 기반으로 Streaming 데이터 처리, Graph 데이터, Machine Learning 등 최근 수요가 많은 부분에서도 추가적인 기능을 제공하고 있습니다.
개발 측면에서 자바로 작성되는 기존 하둡 맵리듀스보다는 Scala 언어를 통해 코드 량을 줄일 수 있습니다. Apache Spark의 경우 Java, R, Python, Scala 등 다양한 언어 인터페이스를 제공하지만, 보다 나은 성능과 Spark의 장점을 충분히 살리기 위해 Scala 언어를 새로 배워야 하는 것은 분석가나 개발자에게 부담이 될 수 있는 부분입니다.
웹 기반 데이터 시각화 : D3.js
분석된 데이터에 대한 가시화(Visualization) 환경을 고려했을 때, 일반적으로 가장 많이 사용되는 웹 플랫폼을 떠올리는 것은 이상한 일은 아닐 겁니다. 물론 웹에서도 HTML5를 지원하는 브라우저 제약 및 대용량 데이터를 브라우저에 효과적으로 표현하기 위한 리소스 관리 및 최적화 이슈를 고려해야 합니다.
D3.js는 웹상에서 다양한 그래프와 차트를 표현해 줄 수 있는 자바스크립트 기반 오픈소스 라이브러리 입니다. D3.js의 뛰어난 유연성과 개발 편의성으로 프로세스 마이닝 분석 결과로 얻어지는 대부분의 사용자 인터랙티브한 시각화 화면들을 구현할 수 있습니다.
앞서 설명한 기술들은 최근 유행하는 기술들의 단순한 모음처럼 보일 수도 있습니다. 이는 프로세스 마이닝 분석 시스템을 구축하기 위한 구현 스택의 하나의 예시로서 프로세스 마이닝 기술을 구현하는데 정답은 없습니다. 기술은 기술 일 뿐 업무 데이터를 프로세스 관점에서 분석하기 위해, 순수한 자바 프로그램으로도 단일 머신에서 돌아가는 프로그램을 구현할 수도 있고, R이나 파이썬 같은 스크립트 언어를 활용하여, 해당 명령어 셸상에서 동작하는 라이브러리 형태로 만들 수도 있습니다.
데이터 분석의 생산성을 높이기 위해서는 지속적으로 반복되는 데이터 분석 사이클 즉, 데이터 수집 – 전처리 – 가공 – 분석 – 리포팅에 이르는 일련의 분석 흐름을 매끄럽게 수행되어야 합니다. 이를 위해서는 각각의 기능들이 유기적으로 구성되어야 하며, 특정 기술에 종속되기보다는 데이터 규모나 적용되는 도메인의 특성에 따라 각 기술들의 장단점을 고려하며 유연하게 적용 계획을 세워야 할 것입니다.