
간단하게 보는 빅데이터 아키텍처 – 하둡
빅데이터 하면 많이 나오는 하둡과 맵리듀스에 대해 살펴보겠습니다.
먼저 하둡은 아파치 재단에 의해 운영되며 아파치 하둡(High-Availability Distributed Object-Oriented Platform)이라고 합니다.
아파치 하둡은 가장 오래되고 활발한 빅데이터 아키텍처 중 하나입니다. 대량의 자료를 처리할 수 있는 분산 응용프로그램을 지원하는 무료 자바 소프트웨어 프레임워크입니다. 원래 너치(루씬을 기반으로 하여 만든 오픈 소스 검색 엔진)의 분산 처리를 지원하기 위해 개발된 것으로, 아파치 루씬의 하부 프로젝트입니다. 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템과 맵리듀스를 구현한 것을 하둡이라 합니다.
맵리듀스는 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작하여 2004년 발표한 소프트웨어 프레임워크입니다. 맵리듀스는 페타바이트 이상의 대용량 데이터를 신뢰도가 낮은 컴퓨터로 구성된 클러스터 환경에서 병렬 처리를 지원하기 위해서 개발되었습니다. 맵리듀스는 함수형 프로그래밍에서 일반적으로 사용하는 Map과 Reduce라는 함수 기반으로 주로 구성되어 있습니다.
Map은 흩어져 있는 데이터를 Key, Value의 형태로 연관성 있는 데이터 분류로 묶는 작업입니다.
Reduce는 Map 작업에서 생성된 데이터 집합에서 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업을 합니다. 예를 들어 배열에 A, B, C, D 가 무작위로 반복될 때 A 3개, B, 2개, C 1개 와 같은 형식으로 Map의 Key로 묶어 분류하게 됩니다.
분산 처리가 가능하기 위해서는 연산 작업이 교환법칙과 결합법칙이 성립되어야 합니다. 데이터를 어떤 서버에서 나눠서 처리하더라도 결과가 달라지면 안 되기 때문입니다. 그렇기 때문에 맵과 리듀스 작업에 대한 설계가 잘 이루어져야 합니다.
문서에서 단어 수를 세는 예로 맵리듀스 처리 순서는 다음과 같습니다.
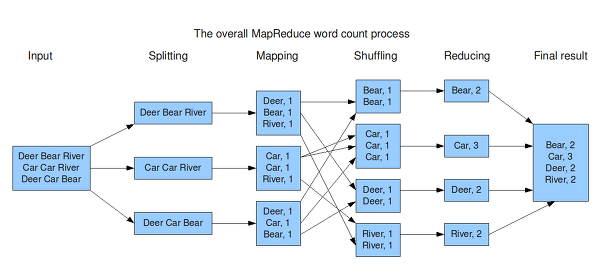
1. Splitting: 입력 데이터를 라인 단위로 분할합니다.
2. Mapping: 분할된 라인 단위의 문장을 Map 함수로 전달하면 Map 함수는 공백을 기준으로 문자를 분리, 단어의 개수를 확인하며 그 결과를 메모리에 임시 저장합니다.
3. Shuffling: 메모리에 저장되어 있는 데이터를 분류하고 정렬하여 디스크에 저장 후 네트워크를 통해 리듀서의 입력 데이터로 전달합니다.
4. Reducing: 전달된 데이터를 반복적으로 수행하여 단어 수의 합을 계산합니다.
이런 맵리듀스 작업을 통해 아주 많은 데이터에서 특정 통계치를 뽑아내는 등의 작업이 가능하게 됩니다.
하둡은 기본적으로 다음과 같은 모듈을 포함하고 있습니다.
이상 하둡에 대해 간단하게 살펴보았습니다.
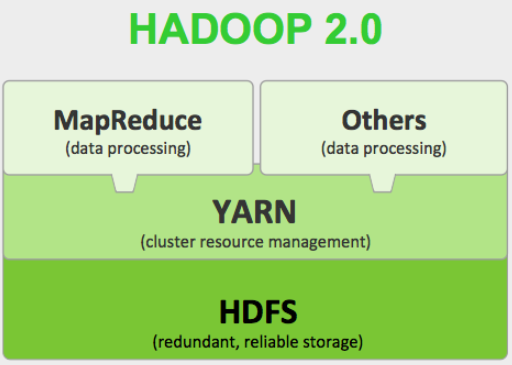
– Hadoop Common : 다른 하둡 모듈을 지원하기 위한 공통 유틸리티
– Hadoop Distributed File System (HDFS) : 데이터에 접근하기 위한 높은 가용성을 제공하는 분산파일시스템
– Hadoop YARN : 작업을 스케줄링하고 리소스를 관리하는 프레임워크
– Hadoop MapReduce : YARN을 기반으로 한 병렬처리 시스템
이 외에 아파치 스파크와 같은 다른 많은 요소들을 하둡과 연계하여 사용할 수 있습니다.
