
영화 ‘머니볼’로 보는 프로세스 마이닝 사용 이유
영화에서처럼 각 선수들의 과거 기록과 점수를 라벨링해서
컴퓨터에게 트레이닝 데이터로 학습시킨다면 어떨까?
과거 이력을 바탕으로 우리 팀에 맞는 선수들을 추천해주는 시스템이 있다면?
더 나아가 필드에 내보낸 선수들에 따른 결과를 미리 예측할 수 있다면?
영화 – 머니볼(Moneyball: The Art of Winning an Unfair Game)을 보신적이 있으신가요? 저는 지난 설연휴, TV에서 이 영화를 보았습니다. 우리나라에서는 2011년에 개봉한 조금은 오래된 영화이지만 매우 흥미롭고, 가슴을 뛰게 만드는 영화였습니다.
영화의 스토리는 이렇습니다. 미국 메이저리그팀 중 하나인 ‘오클랜드 애슬레틱스’는 자본이 충분하지 않은 작은 야구 구단입니다. 오클랜드 애슬레틱스는 재정이 부족한 까닭에 이름있는 선수들을 구단으로 끌어오기는 커녕 선수들을 키우는 족족 큰 구단으로 빼앗기고 메이저리그 최하위를 지키고 있었습니다. 어떻게든 구단을 살리고 싶지만 좋은 선수들을 영입할 수 없던 단장 ‘빌리 빈’은 이에 큰 결심을 합니다. 운용 가능한 재정으로 선수 영입이 아닌 예일대 경제학과 출신의 통계 전문가 – ‘피터 브랜든’을 데려온 것입니다.
피터가 각 선수들의 기록으로 통계를 내어본 결과, 출루율이 중요한 요소임에도 그동안 중요하게 평가되지 않아 왔다는 사실을 알게 됩니다. 이제 빌리와 피터는 스타 플레이어들을 내보내고 저평가 되어 있는(출루율이 높은) 선수들을 영입하고자 합니다. 그러나 성공으로 가는 과정은 언제나 그렇듯 쉽지 않습니다. 데이터의 힘을 알지 못하는 구단 임원들의 반대가 어마어마하고, 구단주도 설득해야 합니다. 하지만 빌리와 피터는 그들이 데이터로부터 얻어낸 정보를 믿었고, 결국 오클랜드 애슬레틱스는 그해 처음으로 메이저리그에서 20연승을 거두어냅니다.
이 영화를 보고 나서 심장이 쿵쾅 뛰었습니다. 영화에서처럼 각 선수들의 과거 기록과 점수를 라벨링해서 컴퓨터에게 트레이닝 데이터로 학습시킨다면 어떨까? 과거 이력을 바탕으로 우리 팀에 맞는 선수들을 추천해주는 시스템이 있다면? 더 나아가 필드에 내보낸 선수들에 따른 결과를 미리 예측할 수 있다면?

실제로 많은 곳에서 최고의 선택을 하고, 결과를 예측하기 위한 시도들이 진행되고 있습니다. 우리가 잘 알고 있는 넷플릭스, 유튜브의 영상 추천 시스템, 아마존, 쿠팡의 물류 주문 예측 시스템, 보안업체들의 사이트 분류 시스템들이 그 예입니다.
그렇다면 컴퓨터는 어떻게 영상을 추천하고 주문을 예측하고 사이트를 분석하는 것일까요? 업체 솔루션마다 특화하여 사용하는 분야가 있고 알고리즘이 있지만, 머신러닝의 가장 기본이 되는 개념으로 살펴보자면 우리는 컴퓨터에게 데이터를 주고 공부(학습)를 시킬 수 있습니다.
공부를 시키는 방법은 크게 3가지로 나뉩니다.
1. 문제와 답을 함께 알려주고 비슷한 문제가 나왔을 때 답을 유추하게 하는 방법
(지도 학습: Supervised Learning)
예.
a, b, c 요소를 가지고 있는 A사이트는 유해사이트이다.
d, e, f 요소를 가지고 있는 B 사이트는 정상사이트이다.
b, c, f 요소를 가지고 있는 C 사이트는 유해사이트인가?
2. 분류되지 않은 많은 데이터를 주고 새로운 데이터를 주었을 때 어떤 유형인지 분류하게 하는 방법 (비지도 학습: Unsupervised Learning)
예.
여러 장의 슈퍼맨, 배트맨, 스파이더맨, 헐크, 슈퍼우먼의 사진들 제공
각 히어로별로 구분하여 사진을 분류할 수 있는가?
3. 문제 해결에 따른 보상을 주고 더 큰 보상을 받기 위한 답을 도출하게 하는 방법
(강화 학습: Reinforcement Learning)
예.
체스 경기에서 상대방의 말을 잡을 때마다 보상(득점 처리)
그러나 당장은 득점하지 못하더라도 최종적으로 더 큰 득점을 할 수 있는 경우를 고려해야 함
데이터를 가지고 위의 방법들로 학습을 한 컴퓨터는 우리가 좋아하는 영상들을 분류하여 추천해주고, 주문할 물건들을 예측하여 준비할 수 있도록 하며, 우리 아이가 접속하는 사이트가 유해사이트인지 아닌지를 판단하고 차단해줍니다.
‘퍼즐데이터’에서 연구하고 있는 ‘프로세스 마이닝’도 미처 알지 못했던 저평가된 요소들를 찾고, 앞으로의 일을 예측하며 최상의 선택을 하고자 하는 우리들의 요구와 필요성에 의해 탄생하였습니다.
하지만 프로세스 마이닝은 그 중에서도 특히 패턴과 흐름(프로세스)을 찾아내고 분석하기 위한 기술로, 숨겨져 있던 프로세스를 찾아내거나 알고는 있었지만 눈으로 확인하기 어려웠던 프로세스를 데이터 시각화를 통해 확인할 수 있도록 해줍니다.
그럼 프로디스커버리(ProDiscovery) 툴을 사용하여 프로세스 마이닝이 어떤 것인지 간단히 살펴보겠습니다.
baseball-reference.com에서 오클랜드 애슬레틱스팀의 신화가 탄생한 2002년도의 데이터를 가지고 와서 보여드리고 싶었으나, 프로세스를 찾기에 적합한 데이터를 발견하지 못해 제가 가지고 있던 수리(repair) 예제 데이터를 사용하였습니다. 프로세스 마이닝 분석용 데이터에 대해 궁금하신 분은 “프로세스마이닝 분석을 위한 데이터 요소” https://blog.naver.com/prodiscovery/221058539389 를 읽어보시면 좋습니다.
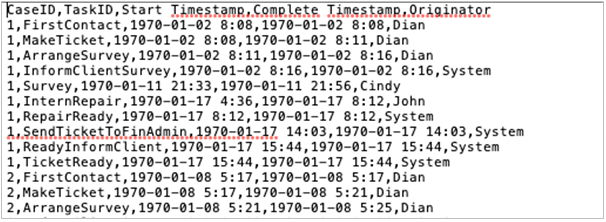
프로세스 마이닝은 시간의 흐름이 있는 로그 데이터로부터 시작됩니다.
로그 데이터를 입력 받은 컴퓨터는 아래와 같이 데이터에 어떠한 흐림이 있는지 분석하여 보여줍니다.

제가 가진 수리 데이터는 FirstContact – MakeTicket – ArrangeSurvey – InformClientSurvey – Survey – (생략) – TicketReady 순으로 진행되고 있는 것을 알 수 있습니다.
간략한 표현을 위하여 위의 맵에서는 복잡도를 낮춰 일부 구간을 생략하였으나, 이번에는 여러 경우의 작업 흐름을 보고 싶어 수행시간이 오래 걸린 상위 4개의 케이스를 조회해 보았습니다.

제가 가진 데이터가 모두 동일한 프로세스로 진행되는 것은 아니었네요.
그럼 위의 결과 중 시간이 가장 오래 걸린 521번 케이스에 대해서 상세 조회를 해보겠습니다.
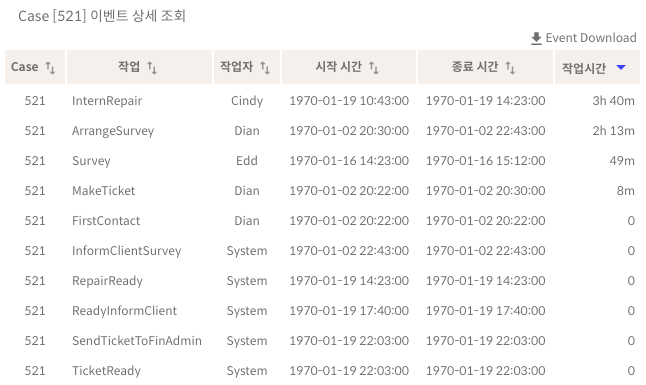
521번 케이스를 살펴보니 각각의 작업 시간은 의외로 짧았습니다. Cindy가 맡은 InternRepair 작업이 가장 오래 걸렸지만 4시간도 안되어 처리되었고, System이 처리하는 작업은 모두 1초도 걸리지 않아 처리되었습니다. 521번 케이스가 오래 걸린 원인은 작업 시간이 아니라 2일-16일-19일로 넘어갈 때 대기 시간이 문제였다는 것을 알게 되었습니다.
가장 간단한 몇가지 그래프만 살펴보았지만, 프로세스 마이닝을 사용하여 어떤 정보를 얻을 수 있는지 알 수 있는 기회가 되셨으면 좋겠습니다.
숨어있는 정보들을 찾아내어 우리 모두 연승하는 그 날까지! 저도 열심히 프로디스커버리(ProDiscovery) 연구 개발에 힘쓰겠습니다.
