
데이터 엔지니어링
개요
데이터 분석가들이 데이터를 통해 프로세스 혁신 및 마케팅 전략을 결정하는 등의 과학적 의사결정을 지원 가능하도록 하는 근간에는 중단 없이 데이터가 수집되어 처리 시스템이 처리할 수 있도록 저장소에 모아 넣는 작업이 뒷받침되어야 한다.
데이터 수집 및 적재, 전처리(이하, 데이터 전처리)는 데이터 분석이라는 큰 목적 안에서 가볍게 여기기 쉽지만 데이터 분석 시 원하는 데이터를 정확하게 그리고 효율적으로 서비스할 수 있으려면 대부분의 데이터 전처리 과정에 많은 주위와 노력을 들여야 한다.
하지만 데이터 전처리 과정에서 데이터 엔지니어에게만 모든 역할을 맡긴다면 결과가 좋게 나올 수 없기에 분석가와의 의사소통이 매우 중요하다.
때문에, 분석에 적절한 데이터를 만들기 위해서 데이터 엔지니어는 전체적인 과정에 대해 면밀히 설계 및 구현하고 잘 정리된 문서나 기타 작업 진행에 대한 내용을 알려 줄 수 있는 도구들을 활용하여 분석가에게 이에 대한 정보를 전달하고 분석가가 좋은 결과를 도출할 수 있도록 지원해야 한다.
일반적으로 아래 세 가지를 알려 주어야 한다.
● 데이터가 어디에 저장되어 있는지 : 분산 파일 시스템이든, 네트워크 드라이브든, 데이터베이스든 어떤 곳에 저장되어 있는지 알려주어야 한다.
● 데이터가 어떻게 저장되어 있는지 : 파일이면 헤더는 어디에 저장되어 있고 각각이 무슨 의미를 갖는지, 데이터베이스면 어떤 테이블에 있으며 스키마 정보는 어떻게 되는지 등을 알려 줘야 한다.
● 데이터를 가져갈 수 있는 방법은 무엇인지 : 데이터베이스면 연결정보, 파일이면 위치 정보, 분산 파일 시스템이면 사용 방법에 대해 설정된 사항들을 알려주어야 한다.
이후 내용에서는 데이터 전처리 과정에 대한 대략적인 내용과 데이터 엔지니어가 실제로 가장 많이 관여하게 되는 Integration 과 Cleansing 과정을, 데이터 분석가의 역할이 더 많이 필요한 Reduction 과 Transformation 과정에 대한 간략한 내용들을 설명한다.
데이터 전처리 과정
데이터 전처리는 그림 1. 과같이 일련의 과정을 거치게 된다. [1] 그림 1. 과 같은 과정을 반드시 순서대로 거쳐야 하는 것은 아니다. 각 과정은 진행과정에서 비 순차적으로 서로의 과정 이후에 여러 번 다시 진행하게 된다.
위 개요에서 설명한 바와 같이 데이터 엔지니어는 데이터를 정제하고 처리하는 데 있어 분석가와의 면밀한 의사소통 과정이 필요하다. 예를 들어, Data Cleansing 과정에서 기본값으로 무엇을 채울 것인지, Noisy Data를 어떤 방식으로 처리할 것인지에 대한 내용을 사전 협의 없이 데이터 엔지니어의 재량으로 진행하면 나중에 큰 곤경에 처하게 된다.
각 단계는 의사소통 과정의 체크포인트 역할을 해주게 된다. 예를 들어, 오늘부터 새로운 테이블을 추가로 통합하여 새로운 데이터 셋을 만들어 달라는 요청이 들어왔다고 가정하자. 기존에 각 과정을 단계별로 잘 관리한 데이터 엔지니어라면 Data Integration 단계로 가서 필요한 부분을 수정하고 반영할 것이다.
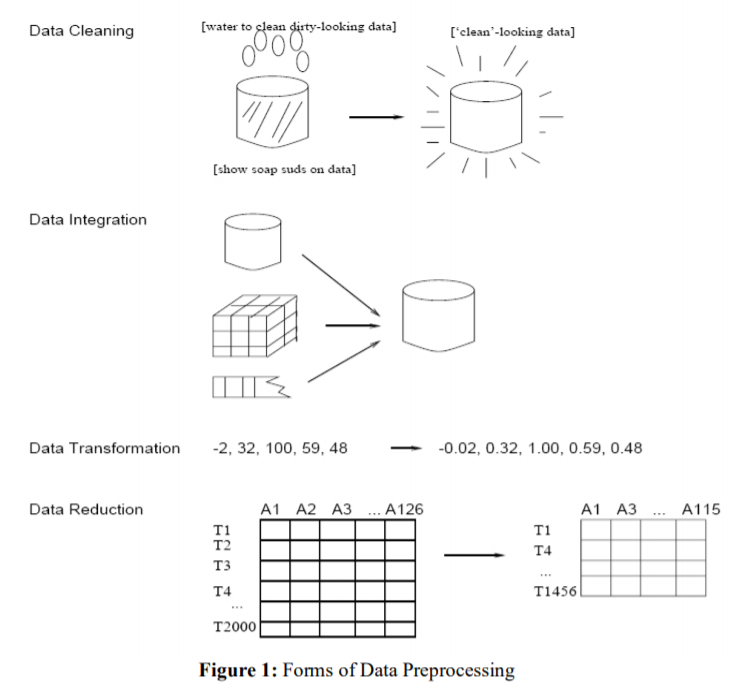
4가지 단계가 모두 어려운 과정이지만, 개인적으로 데이터 엔지니어가 가장 신경을 써야 하는 부분은 Data Cleansing이라고 생각한다.
Data Cleansing
Cleansing 은 크게 4가지 종류가 있다. [2]
● 누락된 데이터 채우기
● Noisy/Outlier 데이터 정제하기
● 일치하지 않는 데이터 교정
● 데이터 통합에서 발생된 중복 해결
각 종류마다 문장 안에 하고자 하는 결과에 대한 뜻을 대부분 담고 있기 때문에 여기서 자세한 설명은 건너뛰고 각각에 대한 자세한 설명은 참고 문헌을 살펴보기 바란다.
Data Cleansing 과정이 다른 과정보다 중요한 이유는, 여기서 잘못 처리된 결과는 나머지 모든 결과에 영향을 미치게 된다. 데이터의 양이 많고 다양해질수록 각각의 과정이 소비하는 시간도 데이터양에 비례하여 증가하게 되기 때문이다.
원하는 분석 결과를 잘 얻도록 하기 위해 Raw 데이터가 원하는 형태대로 잘 정제 혹은 교정되었는지 Data Validation 계획을 잘 세우고, Data Integration 단계에서 불필요한 데이터가 폭발적으로 증가되는 현상을 방지할 수 있게 많은 주위를 기울여야 한다.
Data Integration
[4]에서 언급하듯이 가트너의 연구에 따르면 빅데이터 인프라를 구성하는데 가장 큰 도전과제는 Variety라고 한다.
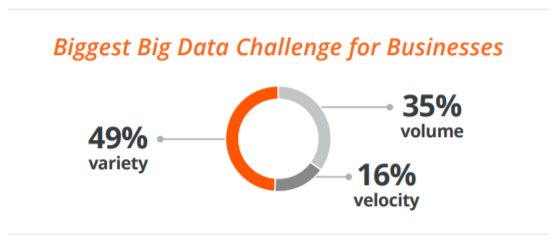
다양성이 가장 어려운 도전 과제인 이유는 데이터 소스 수 증가, 새로운 데이터 유형 증가, 데이터가 있는 위치 및 생성되는 데이터의 양이 증가하기 때문에 이들을 통합하여 각 데이터 별로 연관성을 찾아 하나의 통합된 데이터로 만들어야 하기 때문일 것이다.
이 작업은 한 번 한 번의 시도 자체가 상대적으로 다른 과정보다 많은 시간을 소요하기 때문에 각 소스 시스템마다 작은 데이터를 수집하여 통합된 결과 샘플을 분석가와 의논하고 최종 확정이 되면 전수 데이터에 대해 작업하는 것이 효율적이다.
Data Transformation
Data Transformation 은 데이터 엔지니어의 역할보다는 분석가의 역할이 크다. Transformation 을 수행하는 이유는 적절하게 모델을 향상시키기 위한 것으로 값에 특정 상수를 곱하는 Scale Tranformation이나 Log Transformation 등 데이터의 수학적 변환이 주로 수행된다.
Data Reduction
너무 큰 데이터로 작업을 하는 것은 분명 비효율 적이다. 필요한 데이터를 선택하고 중요하지 않은 속성은 제거하거나 데이터의 양을 줄이기 위해 샘플링하는 방법이 있다.
결론
지금까지 데이터 전처리 과정에 대해 살펴보았다. 사실 데이터 전처리 과정은 개발을 통해 하나씩 제어 하기란 매우 어렵다. 따라서 보통 GUI 기반 도구의 도움을 받는다. [3]
위에서 설명한 과정 이외에도 운영에 반영하여 지속적인 통합, 정제를 수행하는 방법, 원천 데이터의 변형을 안정적으로 반영하기 위한 방법 등 데이터 처리와 관련된 기술과 방법론은 정말 다양하다.
하지만, 복잡하고 어려운 데이터 엔지니어링의 세계에서 이미 많은 사람들에게 익숙하지만 반드시 명심해야 할 한 문장을 소개하며 데이터 엔지니어링에 대한 설명을 마친다.
“Garbage In, Garbage Out”
[참고 문헌]
[1] http://iasri.res.in/ebook/win_school_aa/notes/Data_Preprocessing.pdf , Data Preprocessing Techniques for Data Mining – IASRI
[2] https://www.cse.wustl.edu/~zhang/teaching/cs514/Spring11/Data-prep.pdf, Data Preprocessing, 8-15
[3] Erhard Rahm, Hong Hai Do, Data Cleaning: Problems and Current Approaches
[4] https://datavirtuality.com/wp-content/uploads/sites/2/2018/11/The-Complete-Guide-to-Data-Integration.pdf , The Complete Guide to Data Integration
