
The meaning and selection methods of Case ID in Process Mining
Wonhwi Ko| Feb 2 2022| 15 min read
Case ID selection in process mining is important as it defines the scope of the process being analyzed, impacting the resulting process map, statistics, and execution time calculations.
Understanding Process Mining Concepts for Practitioners
In process mining, there are three essential elements: Case ID, Activity, and Timestamp. You can refer to Understanding Process Mining Concepts for Practitioners (Part 1) for an explanation regarding these essential elements.
A simplified definition of the essential elements is as follows.
● Case ID: This is a column that can represent a single process. A process typically has a beginning and an end, and the Case ID column is selected to have the same value for the entire duration of the process, from its start to its completion.
● Activity: This is a column that can represent the tasks or activities within a process. It should contain values that effectively describe the tasks being performed as the process unfolds.
● Timestamp: This is a column that can represent the time at which events or activities occur within a process. It should contain timestamps that record when events are logged.
However, having only these simple explanations might not make it easy to fully grasp the significance of the essential elements. Today, I aim to provide a more detailed understanding of the meaning of Case ID, which is one of the essential elements.
When initially examining a dataset, it can be challenging to determine which column should be chosen as the Case ID. The reason for this challenge is often a lack of understanding regarding the significance of specifying a Case ID in process mining. Once you grasp the meaning behind designating a Case ID, it becomes easier to select it from the dataset.
A simple definition of Case ID is that it’s a column that can represent a single process. However, I believe a more appropriate interpretation is that it’s a column that defines the scope of a process. Therefore, selecting a Case ID is an act of defining the scope of a process. I’ll explain this in more detail using an example.
The data analysis process involves the following steps:

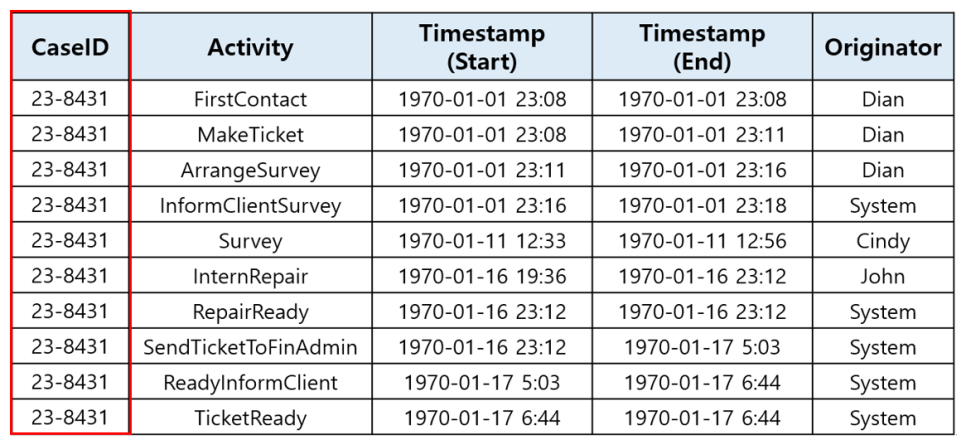
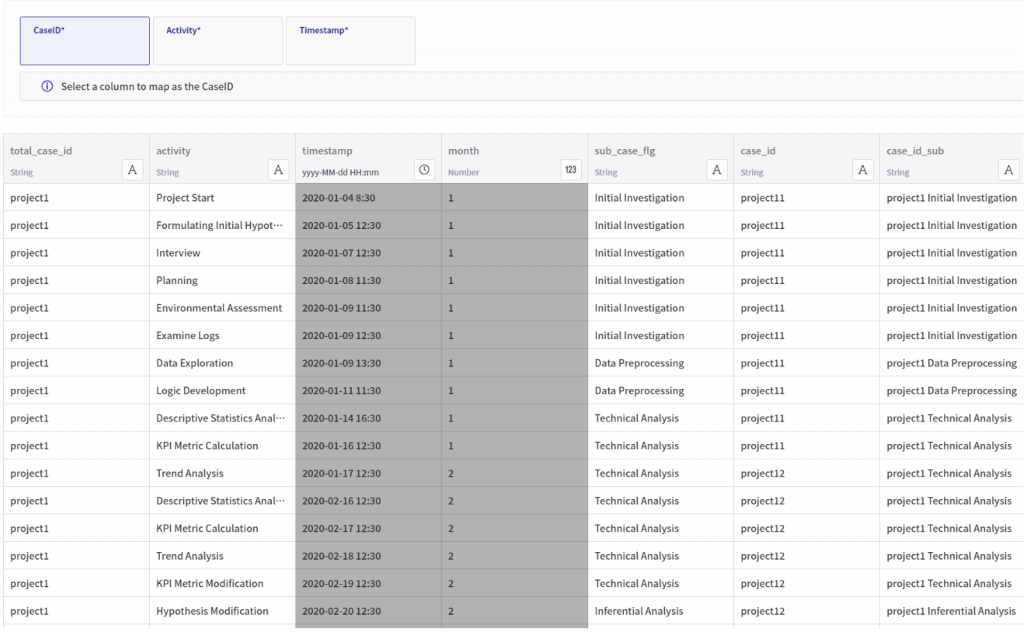
The example dataset (original) is as follows:
The dataset in question is an event log recorded during data analysis projects. These projects spanned a total of three months, with one project conducted in January, another in February, and a third in March, each focusing on a different topic.
Here is an explanation of each column:
● Total_case_id : The project’s name
● Activity: The tasks performed during the project
● Timestamp: The time recorded when a task begins
● Month: The month in which the task was performed
● Sub_case_flag : The nature or category of the task performed during the data analysis project.
Case ID : Total_case_id
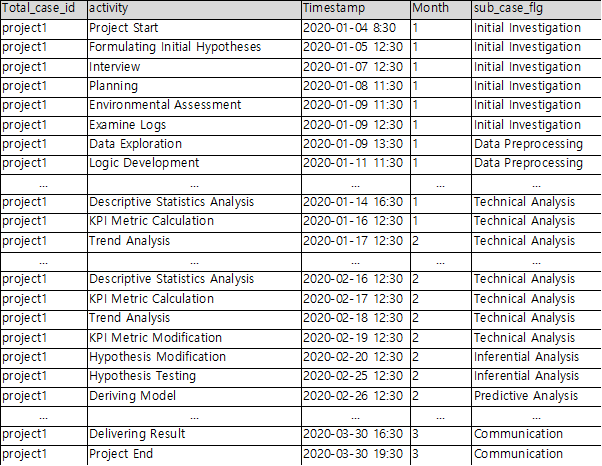
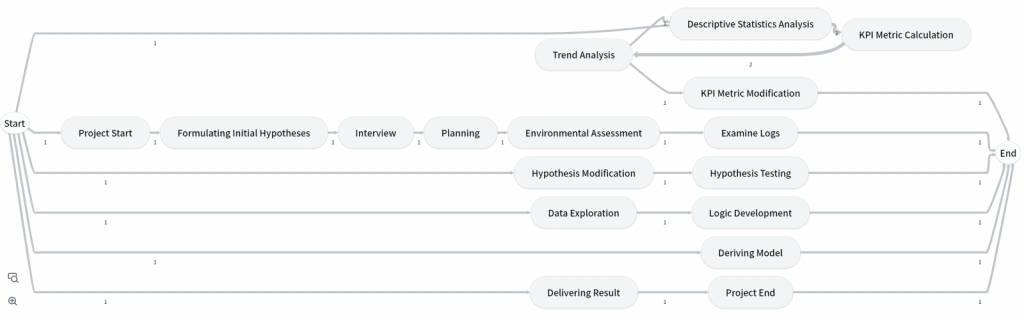
I have decided to conduct process analysis on the data analysis projects. In this context, each project represents a single process. In the example dataset, the start and end of each project are indicated by the “Project Start” and “Project End” activities. The column that holds the same value for each project from start to finish is “Total_case_id.” Therefore, I have designated “Total_case_id” as the Case ID, and when represented as a process map, it looks as follows:

I can confirm that the start of the process is indicated by the ” Project Start” activity, and the end of the process is indicated by the “Project End” activity.

One particular noteworthy aspect is the return to the “Descriptive Statistics Analysis” activity after the “Trend Analysis” activity. This is because in the actual data, after delivering results, the process returns to the “Logic Development” activity before starting a new topic.
Case ID : Case_id
I’ve decided to conduct process analysis on a data analysis process related to a single topic this time. In the example dataset, there isn’t a specific column that directly indicates the start and end of a data analysis process for a single topic. However, we do have information that each month corresponds to one topic, and there is a “Month” column available. By combining the “Total_case_id” and “Month” columns, we can obtain a column that represents the start and end of a data analysis process related to a single topic.
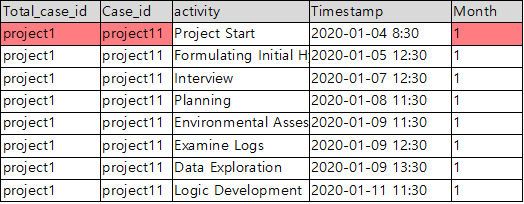
Case_id = Total_case_id + Month
If you designate “Case_id” as the Case ID and represent it as a process map, it would appear as follows

It’s interesting to note that while using the same dataset, the process map has changed. The most significant change is that the process start is divided into three activities: ” Project Start “,” Trend Analysis” and “Delivery Result”.

The process map is broadly divided into two sections. The upper section represents the process where initial data exploration for the project is conducted. The lower section follows the routine process of data preprocessing →exploratory analysis → modeling, →result delivery.
Case ID : Sub_case_id
Process mining primarily uses system logs, which record events at a lower level of detail. Unlike the data analysis processes we are familiar with, the recorded event logs capture even lower-level information. Therefore, it is often more appropriate to analyze specific parts (subprocesses) of the overall process.
e.g) a subprocess such as ‘Data Preprocessing’

This time, I’ve decided to conduct process analysis specifically on the data preprocessing stage within the data analysis process. In the example dataset, there isn’t a specific column that directly indicates the start and end of the subprocess. However, within the data analysis process, there is a “Sub_case_flag” column that denotes the nature or category of the tasks. By combining the “Case_id” and “Sub_case_flag” columns, we can obtain a column that represents the start and end of the data preprocessing stage.
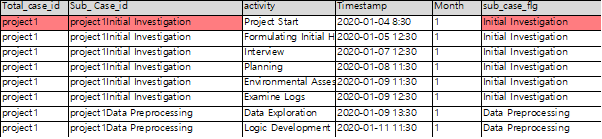
Sub_case_id = Case_id + Sub_case_flag
If you create a new column “Sub_case_id” as the combination of “Case_id” and “Sub_case_flag” and designate “Sub_case_id” as the Case ID, your process map for the data preprocessing stage would look as follows:
The process map has changed once again. The types of process start and end events have become more diverse, and the average length of the processes has shortened. This indicates that the processes have become more fragmented and subdivided. These subdivided processes represent sub-processes that capture the finer-grained steps within the overall process.
When altering the analysis focus to a different process, the process scope naturally adapts. Consequently, as the scope undergoes modifications, the Case ID also shifts, thereby impacting the process map. Rather than directly selecting a column from the dataset to assign as the Case ID, the approach involves defining the target process and subsequently choosing or generating a column that encapsulates that process as the Case ID. In some cases, a combination of multiple pieces of information may be used to formulate the Case ID before its designation.
If you have decided to apply process mining to log data, I recommend the approach of clearly defining the process you want to analyze and specifying the Case ID from the data, as I have done.
One important point to note when changing the Case ID is that it not only affects the process map but also leads to changes in the statistics of all puzzles within ProDiscovery’s internal framework.
Before diving into the explanation, let’s discuss Process Models. There are various types of process models. For instance, developers use flowcharts to model processes, use Petri nets for modeling networks, and process analysts use BPMN to model business processes. BPMN is often used to model business processes, and it includes a wealth of information beyond just process flows.
Here’s an example of a business process modeled using BPMN:

(source : en.wikipedia.org)
The example Process Model you provided not only represents the flow of the process but also includes decision points, rules, and associated resources. In reality, a Process Model is not limited to just the sequence of activities. Depending on the purpose, it can incorporate various contextual information about the process, such as actors, personal aspects, social aspects, external factors, and more.
Process Mining automatically derives Process Models from log data, and the essential information required for this is Case, Activity, and Order. If you refer to the Process Mining Event Log concept, you’ll notice that you need to choose between Position and Timestamp, but you only need one of them. The reason for choosing one between Position and Timestamp is that if either of these pieces of information is available, it can determine the sequence of activities, allowing for the modeling of the basic process flow.
(source : Process Mining , Wil van der Aalst, Second)
Currently, ProDiscovery supports Timestamp as the primary information source, with Case, Activity, and Timestamp designated as mandatory elements when creating a dataset in the event source. In most IT systems, position information is not available in log data, and since Timestamps are recorded, using Timestamp alone typically doesn’t pose significant issues.
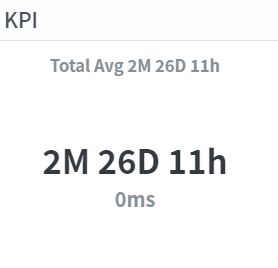
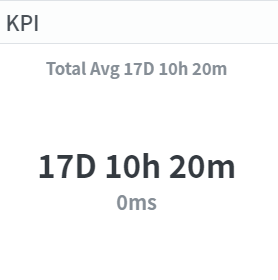
Since ProDiscovery primarily uses Timestamp as the basis, it automatically generates performance information based on time. In this context, all time calculations are relative to the Case ID. Here are the average lead time for each case ID(total case id, case id, sub case id)
Total Case ID

Case ID

Sub Case ID


The change in average process execution time when considering Total Case ID, Case ID, and Sub Case ID as the basis makes sense when you understand how Case ID selection affects the scope of analysis. Case ID essentially represents the scope of the process being analyzed. So, when you change the Case ID, you are changing the scope of the process, which naturally results in changes in execution time.
1.The average execution time based on Total Case ID is 2 months and 26 days. This reflects the total time taken for an entire project.
2. The average execution time based on Case ID is 17 days and 10 hours. This represents the time taken to analyze a single topic within the project.
3. The average execution time based on Sub Case ID is 8 days and 10 hours. This reflects the time taken for a specific step or phase within the analysis process.
There is another important point to be aware of. The total execution time for Total Case ID is 2 months and 26 days, which is approximately 2075 hours. The total execution time for Case ID is 20 days, 23 hours multiplied by 3, which is approximately 1509 hours. Some might wonder about the difference between these two values.
The reason for this difference is that in the Case ID approach, the waiting time between the completion of one topic and the start of the next one is not included in the Case ID’s total execution time. However, in the Total Case ID approach, this waiting time is included, which accounts for the longer total execution time.
The waiting time between different topics or phases within the project, as highlighted in red, represents the waiting time until one topic within the Case ID is completed, and the next topic begins. This waiting time can be confirmed through the data, as shown below.
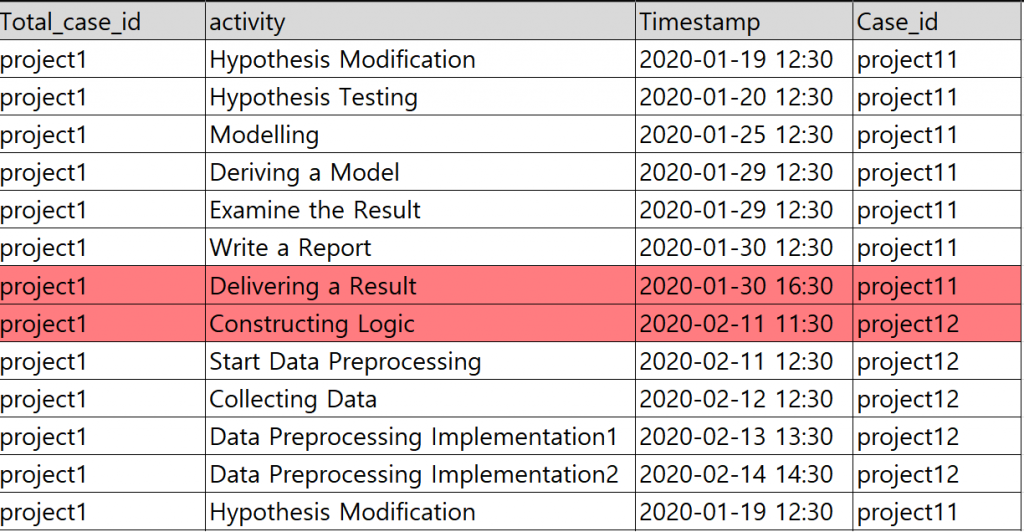
When using Total Case ID, the time between 2020-01-30 12:30 and 2020-02-11 11:30 is included as waiting time in the total execution time. However, when using Case ID, the time between 2020-01-30 16:30 and 2020-02-11 11:30 is excluded from the execution time.
It’s important to note this when analyzing processes with hierarchies like (Process-Sub Process). When analyzing sub-processes, be aware that waiting times between sub-processes, such as transitioning from one sub-process to another, are not included.